Research on Complex Environment Adaptation Technology and Its Algorithm for Intelligent Networked Vehicles

Online veröffentlicht: 17. März 2025
Eingereicht: 17. Okt. 2024
Akzeptiert: 26. Jan. 2025
DOI: https://doi.org/10.2478/amns-2025-0192
Schlüsselwörter
© 2025 Fan Luo et al., published by Sciendo
This work is licensed under the Creative Commons Attribution 4.0 International License.
With the rapid development of artificial intelligence and Internet of Things (IoT) technologies, smart internet-connected vehicles have become the focus of much attention in the automotive industry [1-2]. By integrating traditional automobiles with Internet technology, smart connected car systems enable vehicles to communicate and exchange data in real time with other vehicles, road infrastructure, and cloud servers. This new automotive system is not only expected to improve traffic efficiency and reduce traffic accidents but also help provide drivers with a more convenient and comfortable driving experience [3-4].
However, the rapid development of intelligent connected vehicle systems also brings a series of safety hazards and challenges. Unlike traditional cars, smart connected vehicle systems face more security threats, such as hacking, data leakage, and system failure. Once a security problem occurs, it may lead to serious consequences and even endanger personal safety. Therefore, ensuring the security of smart connected vehicle systems has become one of the important problems to be solved at present [5-7]. In order to ensure the safety of the system, formal methods have been introduced into the field of intelligent vehicles for safety verification. Formal methods are considered to be an effective method for system safety verification, which helps to identify potential problems and risks in system design by establishing mathematical models and formal specifications for rigorous analysis and verification of the system [8-10].
With the booming development of smart connected cars, it becomes crucial to build a safe and efficient environment sensing and decision-making system. The environment sensing and decision-making system for smart connected vehicles is a highly integrated and complex system, which integrates advanced sensor technologies, data processing algorithms and machine learning technologies in order to achieve all-round sensing of the environment around the vehicle [11-12]. By carrying a variety of sensing devices such as radar, lidar, camera, ultrasonic sensors, etc., the environment sensing and decision-making system for smart internet-connected vehicles can accurately capture the position, speed and expected path of the surrounding objects and then fuse and process this information to generate an accurate environment model. Based on this model, the system can use complex algorithms to predict changes in traffic conditions and accordingly plan the vehicle’s travelling trajectory, adjust the speed, and perform the necessary driving operations to ensure driving safety and comfort [13-15]. At the same time, the system is also capable of communicating with other vehicles and traffic infrastructure, i.e., V2X communication. This not only enhances the vehicle’s ability to sense hazards at long distances and out of view but also enables the vehicle to take countermeasures in advance, which greatly enhances traffic efficiency [16-17].
With the continuous progress of science and technology, people’s requirements for the transport system are increasing, and intelligent transport has emerged, which leads to a gradual increase in the demand for intelligent networked vehicles (I-NVs). As an emerging means of transport, intelligent networked vehicles are regarded as an important part of the future transport system, with automatic driving, intelligent navigation and other functions which can enhance traffic efficiency, reduce traffic accidents, and improve the travelling experience of passengers. Literature [18] analyses the types of attacks and defensive measures suffered by intelligent networked vehicles at present, including network security, malware, software vulnerability detection and other fields, and finally also discusses the future development trend of research related to the defense strategy of malicious attacks on intelligent vehicle systems. Literature [19] proposes the GS1 connected car concept, which aims to build an integrated vehicle information platform and ecosystem and demonstrates through practice that the proposed platform can effectively expand the service scope of future intelligent connected vehicles. Literature [20] attempts to discuss the smart connected car technology from three perspectives: system architecture design, functional technology and practice, including sensing, decision-making and control technology involving real complex traffic scenarios and focuses on the technology of each application scenario of smart connected car and the future development trend. Literature [21] reviews the relevant research literature on self-driving car technology, reveals the current status of the development of the current self-driving car technology, and finally classifies the intelligent car driving technology, as well as analyses the existing car-following model, which makes a positive contribution to the research and development of the automotive self-driving technology. Literature [22] designed a global path planning algorithm based on Dijkstra’s algorithm, and at the same time, a dynamic window algorithm was used to conceptualise a local path planning strategy, and a simulation experiment was carried out in the indoor environment map established based on SLAM technology, which confirms that the proposed path planning method can help intelligent cars achieve the drawing of environment maps, path planning and navigation. Literature [23] envisioned a queue length sensing framework based on V2X technology as an infrastructure to achieve queue length prediction for subsequent unconnected vehicles, supplemented with a BP neural network-based sub-model for real-time queue length prediction, and finally validated the validity by using a simulation experiment method.
With the rapid development of smart connected vehicle technology, the introduction of environmental sensing and decision-making systems is seen as a revolutionary advancement in the automotive industry. However, this progress is not without challenges. The environment sensing and decision-making system for smart connected vehicles must be able to process massive data from complex traffic environments and respond in real time while also ensuring the accuracy and reliability of decision-making to avoid safety risks. Literature [24] systematically reviews the related research progress and algorithm applications of environment sensing, path planning, etc., for intelligent self-driving cars and also summarises the problems and deficiencies of car interconnection, car cooperative sensing, and complex interconnected decision-making, which provides an important reference for the research of intelligent car researchers. Literature [25] designed a human-like driving model, which includes a road detection and recognition strategy based on a convolutional neural network and a trained decision-making model, used depth information to build a perception system and confirmed the robustness and feasibility of the proposed model through experiments. Literature [26] describes that intelligent vehicles can perceive the surrounding complex environment, the ability to extract road information, and the ability to avoid obstacles, and split the intelligent vehicle perception technology into perception technology, communication technology and communication-perception fusion technology, and carry out more in-depth analyses and researches. Literature [27] introduced the image content analysis technique as an important environment sensing technique for smart vehicles, conceived a single-stage supervised deep hashing framework (SDHP) to learn high-quality binary codes, and confirmed that the proposed framework effectively improves the environment sensing and searching accuracy of smart vehicles based on experimental methods. Literature [28] proposed an innovative paradigm of Cognitive Internet of Vehicles (CIoV) in order to solve the problem of stable connectivity of cellular networks, in-vehicle self-organising networks and other architectures for smart car networking, and carried out simulation experiments for demonstration, and finally, further thought and discussion on the problems of novel architectures of car networking.
This paper analyses the adaptive technology of intelligent networked vehicles in complex environments in combination with ADAS technology and takes road target detection technology as an example to explore the specific application of intelligent algorithms in it. In order to enhance the performance of target detection in adaptive driving, the YOLOv5s algorithm is improved and optimised. Firstly, the CBAM attention mechanism is incorporated to enhance the model’s sensitivity and recognition of key features in the image, followed by enriching the model’s ability to capture target details by replacing the original PaNet layer of YOLOv5s with a more efficient BiFPN layer. Then, the C2f module is integrated to further lighten the model structure, and finally, the loss function of the model is improved to accelerate the convergence speed and increase the detection accuracy. To examine whether the target detection model in this paper performs similarly to other models on different datasets, BDD100K, KITTI, and Cityscapes are chosen as experimental datasets.The detection effects of different road targets and environments are also analyzed to verify the effectiveness of this paper’s model in identifying different targets in complex driving environments.
With the development of the new era, traditional cars can no longer meet the diversified driving needs of users, so it is necessary to apply intelligent technology to the car so as to achieve automation, unmanned driving and so on. Intelligent networked vehicles combine advanced information technology with automobiles and manage and control the operation of vehicles through wireless communication, sensing equipment, etc., so as to realise the intelligent operation of vehicles.
In terms of the complex environment perception technology of intelligent networked vehicles, at present, it mainly relies on sensors such as cameras, millimetre-wave radar, LiDAR, high-precision maps and other sensors to achieve the perception of the surrounding environment. Advanced Driver Assistance System (ADAS) uses various sensors installed in the car to sense the surrounding environment at any time during driving, collect data, identify, detect and track static and dynamic objects, and combine them with navigation map data for systematic calculations and analysis, so as to let the driver be aware of possible dangers in advance, and effectively increase driving comfort and safety, and cope with a variety of complex driving environments. This can effectively increase the comfort and safety of driving and cope with various complex driving environments.
The ADAS market has grown rapidly in recent years. While such systems were originally limited to the high-end market, they are now entering the mid-range market, while many low-tech applications are becoming more common in the entry-level passenger car segment. New and improved sensor technologies are creating new opportunities and strategies for system deployment. The primary function of early ADAS technologies was to alert drivers to unusual vehicle or road conditions when the vehicle detected a potential hazard. And for today’s ADAS technologies, active interventions are also common. In general, ADAS usually includes Lane Departure Warning System (LDWS), Lane Keeping System (LKS), Adaptive Cruise Control (ACC), Forward Collision Warning System (FCWS), Automated Parking System (APA), Blind Spot Detection (BSD), Driver Fatigue Monitoring and Warning (DFM), Adaptive Light Control (ALC), Automatic Emergency Braking (AEB), Night Vision (NVD) and other common function systems. In addition to these, pedestrian protection systems, electronic police systems (ISA), navigation and real-time traffic systems (TMC), traffic sign recognition, downhill control systems, and electric vehicle alarm systems are also included. Many ADAS functions have been mass-produced, which not only provides automakers with more differentiated product design options but also provides ordinary consumers with better driving experience and safety.
At this stage, automotive intelligent online systems have become the research focus of the Internet and the automotive industry, among which environment perception is the eye of intelligent driving system, and road target recognition is one of the key technologies to ensure the adaptive and safe driving of automobiles in complex environments. Thus, the following section explores the complex environment adaptation algorithm for intelligent networked cars that utilizes the road target detection model.
In complex and changing traffic environments, the high accuracy and real-time performance of target detection algorithms are crucial for the detection of traffic conditions and the decision-making of intelligent driving systems. Considering that vehicles often encounter complex situations such as bad weather and obstructions in real road environments, traditional target detection algorithms have significant limitations in dealing with these problems. Therefore, this study proposes a novel target detection algorithm based on improved YOLOv5s in order to overcome these problems.
The input, backbone network, neck network, and prediction layer are the main components of YOLOv5s.This network structure has the advantages of small feature width and depth, which makes the algorithm a model that can complete training more quickly in the YOLO series and greatly reduces training time.
YOLOv5s performs three main tasks on the input side: mosaic data enhancement, adaptive anchor frame computation, and adaptive image scaling.
Usually, the performance of a neural network model improves as the size of the dataset increases, so a superior neural network model often requires a large dataset to support it, and a large dataset costs a huge amount of money to produce. Data augmentation improves the generalization ability of a model by processing existing data to generate new data, adding the right amount of noise while increasing the number of data samples.In YOLOv5, Mosaic data augmentation usually takes 4 images and generates new images by random rotation, translation, scaling, and cropping to increase dataset samples and enrich the image background.
In YOLOv5, the acquisition of anchor frames is incorporated into the network model by adaptively calculating the size of the anchor frames before training begins. The adaptive anchor frame calculation first scales the dataset image to a specified size, then uses K-means clustering to obtain the corresponding number of anchor frames, and finally, varies the width and height of the anchor frames through genetic algorithms to obtain the size of the anchor frames.
In target detection, a fixed size is needed as input to the model, but the size of the images in the dataset is often not the same, so the images need to be scaled and then input to the model.
The backbone network of YOLOv5s is mainly designed to provide a number of feature maps of different sizes for subsequent provision, which mainly consists of the Focus module, the CBS module, the CSP module and the SPP module.
The Focus structure is an important structure that differentiates YOLOv5 from previous generations of networks, and the slicing operation is the most important part of the Focus structure. The structure of the Focus module is shown in Fig. 1, which processes the image before it is fed into the backbone network and takes the value of the pixels on the image at every pixel interval so that four groups of images can be obtained. The Focus module is able to take the input images. The Focus module concentrates the width and height information of the input images into the channel space and expands it to 12 channels compared to the original three RGB channels because the number of dimensions in the channel space is expanded to four times the original number of dimensions, which retains the information and reduces the size of the inputs, thus increasing the rate of training the network model. After the Focus module, the result is then subjected to a convolution operation to obtain the feature map.
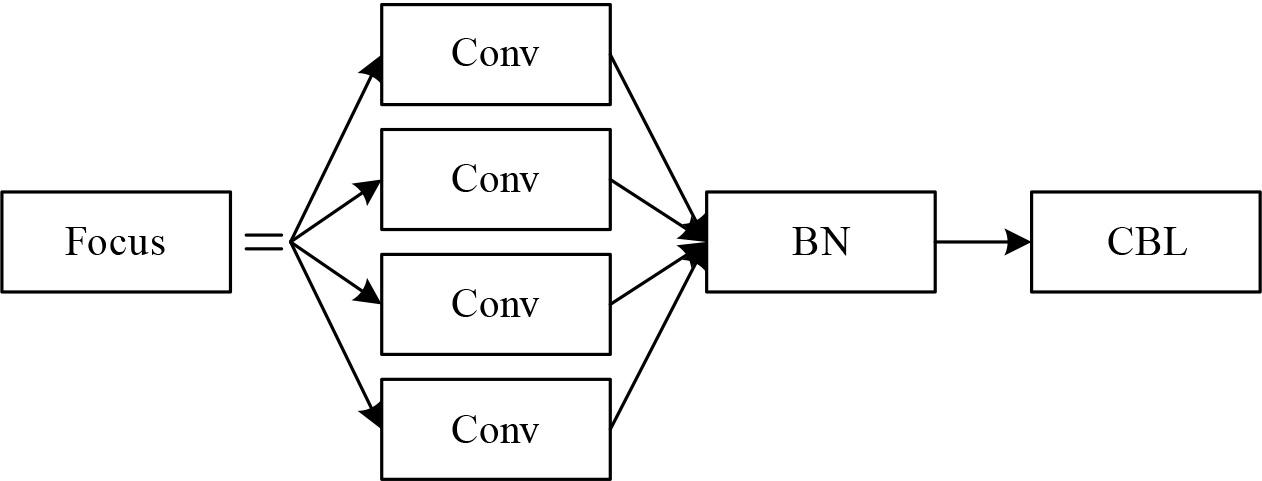
Focus module structure
The Focus structure notably serves the purpose of downsampling, but it is more advantageous than a normal downsampling module. The default input image size is 608×608×3. When downsampling is performed using the ordinary convolution module, the convolution kernel size is 3×3, the step size is 2, the number of output channels is 32, and the feature scale obtained is 304×304×32, and the calculation of FLOPS is calculated as in Eq. (1):
The Focus module slices the feature map size to 304×304×12 through the slicing module and then uses one convolution operation with convolution kernel size 3×3 to get the feature map of size 304×304×32. The calculation of FLOPS is calculated as in Equation (2):
Although the Focus structure is more computationally intensive, about four times as much as the normal downsampling module, it can greatly reduce the loss of information when downsampling the feature map, and the module can be easily integrated into other network structures with wide applicability.
The CBS module consists of three parts: convolution, batch normalisation and SiLu activation, and is mainly used to enhance the feature representation ability of the network. Two CSP structures, CSP1_X and CSP2_X, are designed in YOLOv5s. CSP1_X is applied to the backbone network, while CSP2_X is applied to the neck network. The Spatial Pyramid Pooling SPP module in YOLOv5s employs four kernels of different sizes to perform the maximal pooling operation on the feature maps and splicing of the pooled feature information as output.
The Neck part in YOLOv5s mainly consists of the SPP module, PAN module and FPN module. In the SPP module, the maximum pooling operation is performed by three convolutional kernels of different sizes, and all the results output after pooling are channel-connected with the features that have not undergone pooling, and the local features are fused with the global features. The FPN first constructs a bottom-up pyramid using the pre-training network, and on top of this, the feature pyramid is constructed from the top down after the operations, such as up-sampling and convolution. The PAN A bottom-up path is introduced at the bottom to transfer the feature information from the bottom to the top, compared to the original pyramid, which only needs to go through a small number of convolutional layers.
The Neck module will output three scales of feature maps, i.e., 20×20, 40×40, and 80×80, at the end of the module. The prediction will expand the channel of the feature maps and select suitable prior frames for computation, and based on the comparison of the results with the true values, the loss function will be calculated, and the model will be optimised by back-propagation.
The target detection task generally consists of two parts: classification loss and bounding box regression loss, and the use of the loss function can significantly affect the training speed and detection performance.
The most commonly calculated metric in the bounding box regression loss is the intersection and concurrency ratio
The intersection ratio is one of the important target detection network metrics, which reflects the effectiveness of the detection by judging the degree of overlap between the predicted box and the real box, or the distance between the two. If the two boxes do not overlap,
DIoU reinforces the stability of the bounding box regression. The calculation formula is (5):
In the first step of the operation
Some improvements are made for the Neck and Backbone networks in YOLOv5s to enhance the target detection capability, which includes (1) Adding the CBAM attention mechanism to the upper layer of Backbone’s SPPF module. (2) Adopting the C2f module to replace the previous C3 to enhance the model feature extraction capability. (3) Introduce the BiFPN method to optimise the feature fusion method of the Neck network. (4) Improve the loss function in the original algorithm and replace it with the EIOU loss function to achieve better results. The improved algorithm is named YOLOv5s-CBC.
When detecting road targets, there will be a lot of small-scale targets and occluded targets, which are easily interfered with or affected by the surrounding targets as well as the background, leading to the YOLOv5s algorithm’s omission or misdetection of these targets. To address the above problems, the algorithm can be optimised by using the introduction of an attention mechanism.
The mixed domain attention mechanism (CBAM) is capable of dynamically adjusting the weights of different convolutional blocks according to the image content, thus enhancing the representation of the object in question and reducing the information related to the background noise. Firstly, the channel module is used to correct the input feature map
In the above equation, ⊗ is the element-level multiplication, and
The channel attention module first processes each input feature map. First, global average pooling as well as global maximum pooling of each feature map is performed, which results in 2 feature maps. Then they are inputted into the MLP. The 1st network layer is mainly responsible for dimensionality reduction, and the number of network neurons is
This module can reach the feature maps in the spatial attention module. First of all, GAP and GMP pool the feature maps, and then 2 feature maps can be obtained, and when they are spliced together, a feature map of size 2×
The location in the network architecture where the attention mechanism is incorporated has a significant impact on the feature capturing ability of the model. In this study, we chose to introduce CBAM in the deep part of Backbone to optimise the feature representation of the model and improve the overall performance.
When designing the real-time road target detection model, the complexity and variability of the traffic scene and the natural scene should be fully considered, and YOLOv5s often suffers from the problems of missed detection and false detection when facing targets of different scales. In order to solve this problem and further enhance the effect of multi-scale feature fusion, this paper introduces BiFPN to improve the structure of the PANet network.
Specifically, it includes (1) removing nodes with only a single input, which greatly improves the operation efficiency and processing speed of the model. (2) The added jump connections enable the features at different levels to be directly connected, which not only does not increase the extra computational cost but also ensures the completeness and diversity of feature information. (3) The design of integrating bi-directional paths into a single unit allows this structure to be re-stacked many times, greatly enriching the depth and breadth of feature representation. (4) Finally, there is the organic integration of weighted feature maps. In previous networks, various features were not clearly distinguished and were directly summed. However, BiFPN adopts a weighting strategy so that the importance of features can be effectively adjusted, and its expression can be expressed by Eq. (10):
Here,
Here,
In the Backbone of the original YOLOv5 algorithm, the C3 module is used to extract feature information, but it is easy to lose the information during the road target detection task.In further optimizing the YOLOv5 algorithm, this paper incorporates the C2f module, which can enable the improved network to obtain richer gradient flow information while maintaining lightweight.
By connecting low-level feature maps and high-level feature maps and adjusting their channel numbers and sizes through appropriate convolution operations, the C2f module can effectively transfer information between feature maps at different levels and highly fuse them, thus improving the detection capability of YOLOv5s for targets at different scales.
In order to measure and optimize the performance of a target detection model, the loss function usually contains three main components: classification loss, localisation loss (position loss), and target confidence loss.
In order to improve the convergence rate and make stronger inference, this paper adopts the EIOU loss function as the target frame loss function for the improved model. The EIOU loss function calculation formula is shown in (13):
In the EIOU loss function regression box,
There are many public datasets for traffic scenarios, such as BDD100K, KITTI, Cityscapes and so on. The dataset used in the experimental part of this paper is BDD100K, and to verify the generalization ability of the model, auxiliary verification is performed on Cityscapes and KITTI datasets.
BDD100K is by far the largest and most diverse dataset used in the field of autonomous driving. The images in the dataset were collected in different cities in the U.S., covering different weather conditions: sunny, rainy and cloudy days, and different times of the day and night. A total of 100000 images used for the road target detection task are labelled with buses, traffic lights, traffic signs, people, bicycles, trucks, cars, trains and riders. In this experiment, four categories of Car, Truck, Pedestrian and Cyclist are selected for the experiment, and 5000 images are extracted as experimental data, of which 4000 are used for training and 1000 for testing.
The KITTI dataset is collected in different traffic scenarios such as city streets, country roads and highways, covering Cars, Truck, Van, Pedestrian Tram, Seated Persons, Cyclist, Negligible and Miscellaneous. There are a total of 7,481 annotated images in the KITTI dataset, which are randomly divided into the training, testing and validation sets in the ratio of 8:1:1.
The Cityscapes dataset has 5000 images of driving scenes in urban environments with a resolution of 1024 × 2048 pixels, containing real city street images and fine pixel-level labelling. In this paper, three categories of cars, buses and trucks are kept in the data preprocessing stage. The training set, validation set and test set are divided according to the ratio of 6:1:3.
To assess the performance of the model, the following evaluation metrics are chosen in this paper: precision (P), recall (R), average precision (AP) for each category, and mean average precision (mAP) for all categories.
In order to verify the model performance, YOLOv7-tiny and YOLOv6-N are selected from the more popular target detection algorithms, and the YOLOv5s-CBC model experiments on three datasets, namely BDD100K, KITTI and Citycapes, and the results of the comparison of the different target detection models are shown in Figure 2. The mAP of this paper’s YOLOv5s-CBC model on the three datasets is 88.75%, 89.56% and 83.72%, respectively, which are higher than the remaining three target detection models. The model mAP of this paper is 2.90% higher than that of YOLOv7-tiny, 6.39% higher than that of YOLOv6-, and 5.06% higher than that of YOLOv5s on the BDD100K dataset, which indicates that the optimisation of this paper’s road target detection model is better. Meanwhile, the mAP of the YOLOv5s-CBC model on KITTI and Cityscapes datasets is also significantly improved compared to the original YOLOv5s model, and these results indicate that the improved YOLOv5s-CBC model shows superior performance on different datasets, which further verifies its good generalisation ability.

Comparison results of different target detection models
Uneven distribution of data samples affects model detection accuracy. This is due to the fact that with fewer sample data, there is not enough data to support the model to learn the features of fewer samples to capture the underlying patterns of the data, which leads to limited model generalisation capability. The YOLOv5s-CBC model and the YOLOv5s model are used to detect road targets for cars, trucks, pedestrians, and cyclists in the BDD100K dataset, respectively.
Table 1 shows the detection results of the YOLOv5s model on the BDD100K dataset, and Table 2 shows the detection results of the YOLOv5s-CBC model on the BDD100K dataset. The precision, recall, and accuracy of Truck, Pedestrians, and Cyclists have been significantly improved from 2.62% to 6.90%.In this study, it is expected that the detection model to work better for all classes of counts, not just the common ones. The experimental data show that the model in this paper shows a better improvement effect for data categories with few sample labels, and the average accuracy of the YOLOv5s-CBC model for the detection of four categories of road targets is above 86%, which verifies the effectiveness of the model in this paper. The YOLOv5s-CBC model has a better effect on the detection of various types of targets in traffic roads, and it can assist intelligent networked vehicles in adaptively coping with various complex road conditions.
| Class | Images | Labels | P/% | R/% | mAP@0.5/% |
|---|---|---|---|---|---|
| All | 4000 | 10399 | 84.27 | 83.93 | 85.05 |
| Car | 1000 | 9321 | 92.57 | 90.18 | 91.95 |
| Truck | 1000 | 254 | 85.92 | 81.62 | 83.69 |
| Pedestrian | 1000 | 372 | 86.53 | 87.20 | 84.33 |
| Cyclist | 1000 | 452 | 83.85 | 85.15 | 82.79 |
| Class | Images | Labels | P/% | R/% | mAP@0.5/% |
|---|---|---|---|---|---|
| All | 4000 | 10399 | 89.42 | 88.9 | 90.68 |
| Car | 1000 | 9321 | 95.61 | 94.08 | 93.59 |
| Truck | 1000 | 254 | 90.92 | 88.52 | 87.64 |
| Pedestrian | 1000 | 372 | 89.43 | 91.75 | 89.59 |
| Cyclist | 1000 | 452 | 86.47 | 89.61 | 86.61 |
The samples in the BDD100K dataset are divided into three different environments: sunny, rainy, and night. Figure 3 shows the training loss curves of the model, in which the black curve is the loss curve of the original YOLOv5 road target detection algorithm network training, the red dotted line is the loss curve of this paper’s YOLOv5s-CBC-based road target detection algorithm network training in a sunny environment, the purple dotted line is the loss curve of the loss curve for network training of YOLOv5s-CBC based road target detection algorithm in rainy day environment in this paper, and the green dotted line is the loss curve for network training of YOLOv5s-CBC based road target detection algorithm in night environment in this paper. The loss curves show that the YOLOv5s-CBC-based road target detection algorithm applicable to different environments in this paper converges faster; basically, 35 iterations will complete convergence, and the YOLOv5 road target detection algorithm needs 60 iterations to complete convergence.
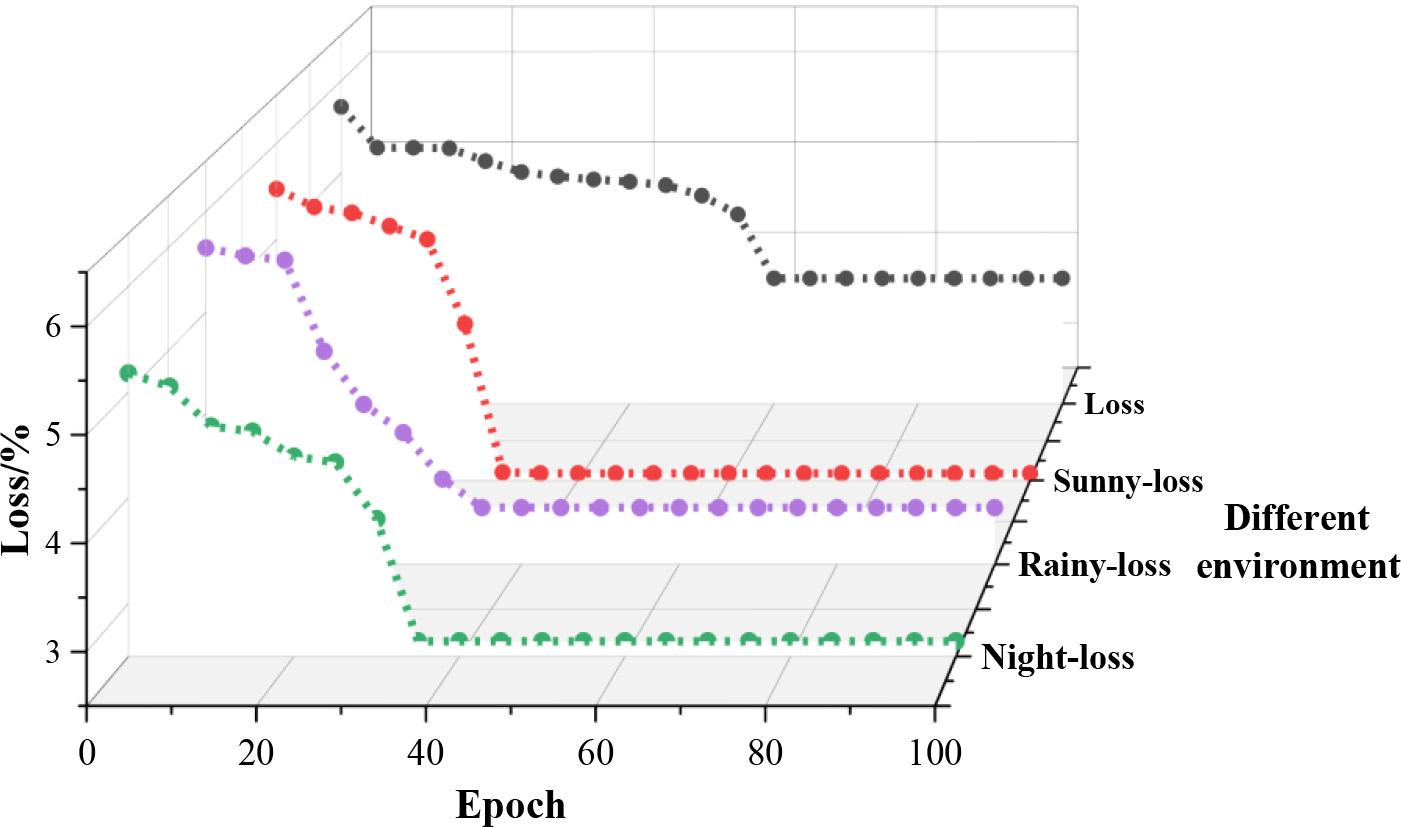
Model training loss curve
With the original YOLOv5 road target detection algorithm model trained above and the YOLOv5s-CBC road target detection algorithm model from this paper, which is applicable to different environments, the road target detection accuracy of the models is tested by using a test set to test the road target detection accuracy of the YOLOv5 model and the YOLOv5s-CBC model from this paper by using the test set for Car and Pedestrian as an example. AP values for these two types of road target detection results. Figure 4 shows the target PR curves of the YOLOv5 model under different environments, where (a) to (c) are the detection results of Car under sunny, rainy and nighttime, and (d) to (f) are the detection results of Pedestrian under sunny, rainy and nighttime, respectively. Figure 5 shows the target PR curves of the YOLOv5s-CBC model in different environments, where (a) ~ (c) are the detection results of Cars under sunny, rainy and nighttime, and (d) ~ (f) are the detection results of Pedestrian under sunny, rainy and nighttime, respectively.
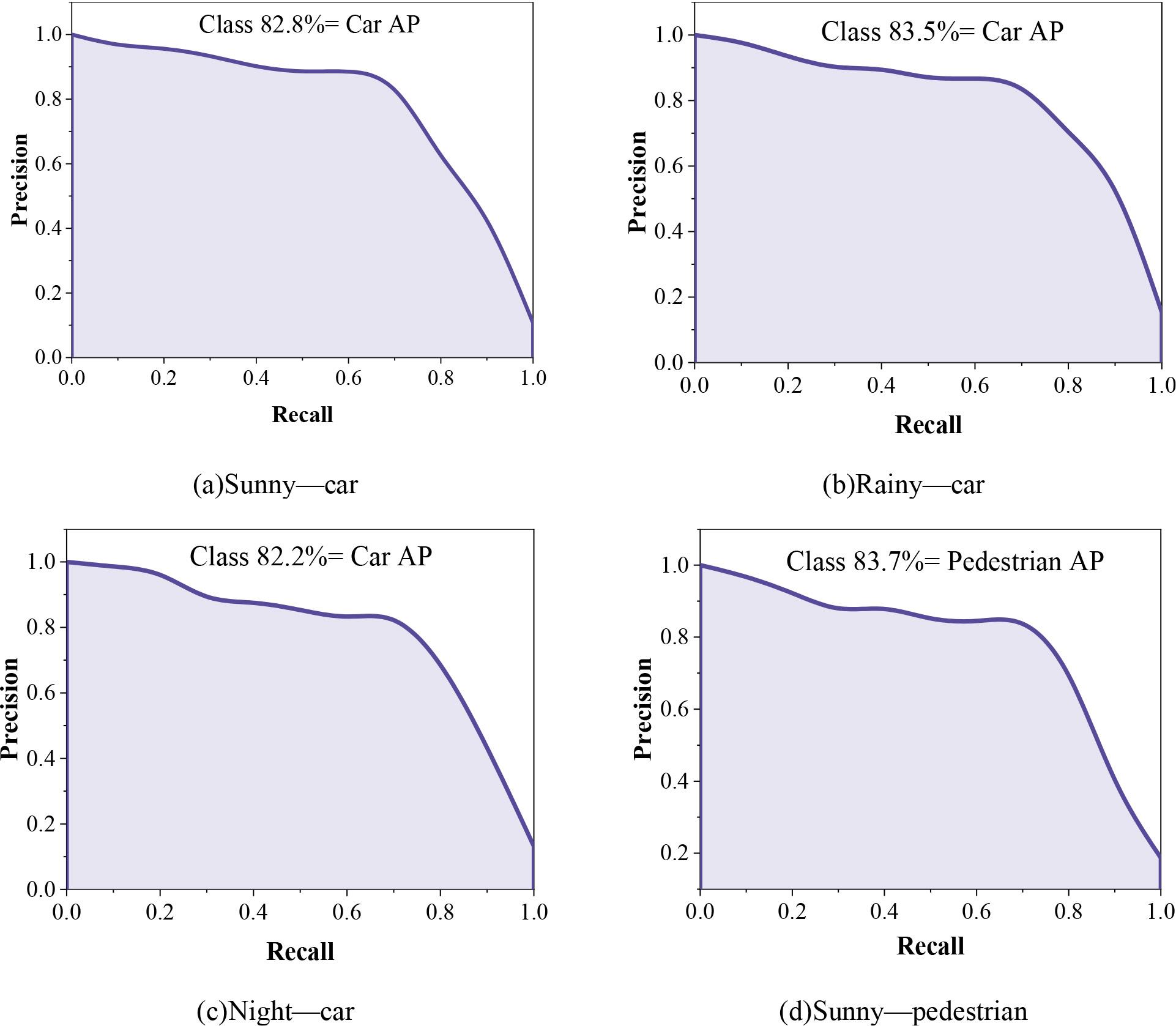
The target PR curve in different environments of the YOLOv5 model
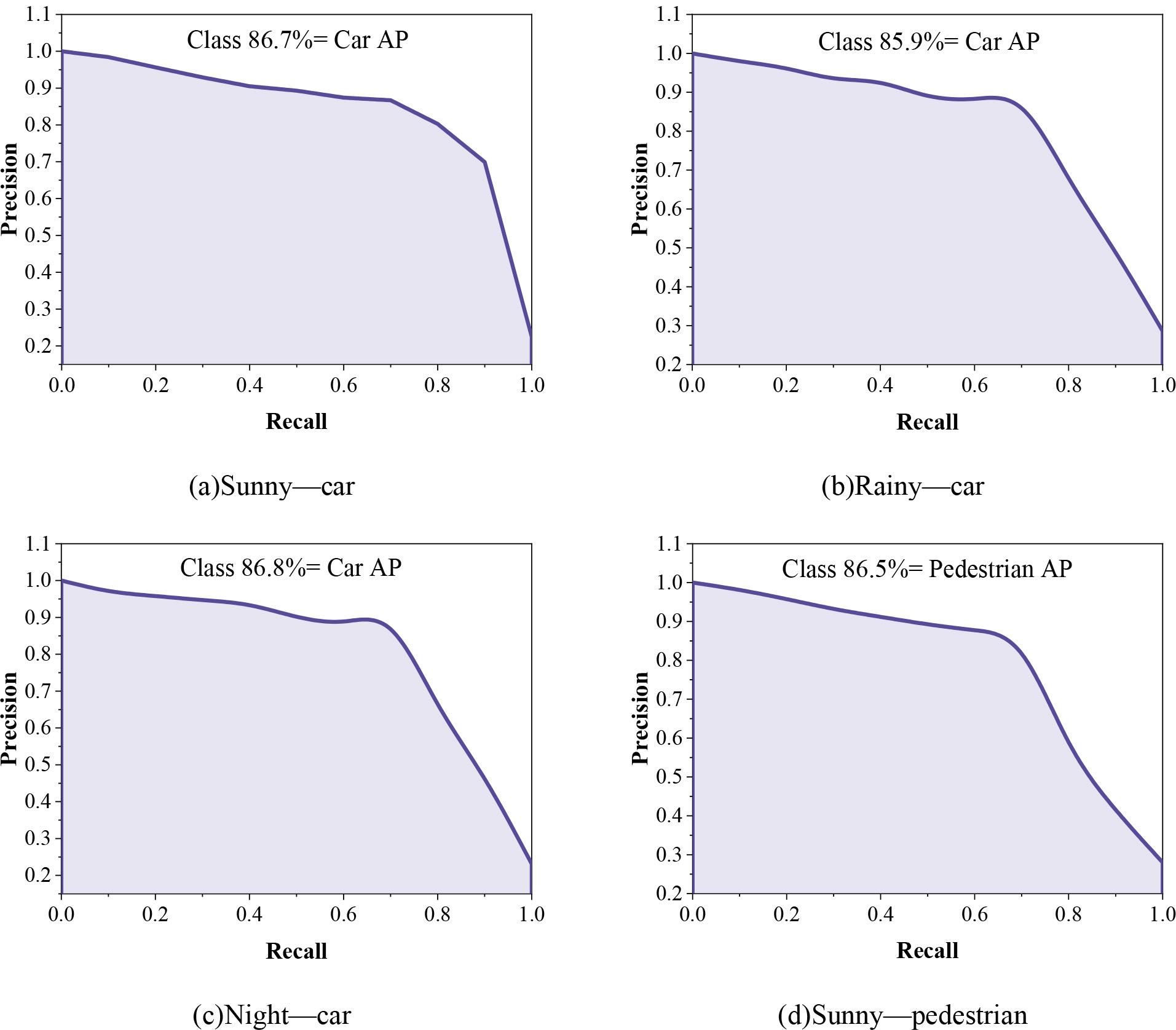
The target PR curve in different environments of the YOLOv5s-CBC model
The average category accuracy mAP of the YOLOv5s-CBC road target detection algorithm for different environments in this paper is 86.6% for its road target detection in different environments of sunny, rainy, and night, while the average accuracy mAP of the YOLOv5 model in different environments is in the range of 82.4% to 83.4%. Compared with the original YOLOv5 road target detection algorithm, the average category accuracy of this paper’s algorithm for road target detection in different environments is improved to a certain extent, and the average category accuracies in sunny, rainy, and night environments are improved by 3.35%, 3.25%, and 4.20%, respectively. This paper’s algorithm has a stronger detection rate for targets in such complex environments as rainy days and nights, while this paper’s algorithm has a not insignificant improvement in road target detection accuracy for pedestrians, a class of small targets, in different environments. In this paper, YOLOv5s-CBC can be used for different road target detection of intelligent connected vehicles in complex weather environments.
With the rapid advancement of science and technology, intelligent networked vehicles have emerged as the primary trend in automobile development in the new era. This topic utilizes the adaptability technology of intelligent networked vehicles in complex environments as its starting point and provides a summary of the application of advanced assisted driving systems in automotive applications. Taking target detection technology as an example, the road target detection model based on the improved YOLOv5s algorithm is constructed, and its target detection effect in different environments is explored. The study yielded the following main results:
ADAS technology gathers complex environmental information during automobile driving through sensors, analyzes, rationalizes, and judges it, and then generates corresponding control instructions based on the results to achieve vehicle control. It can use intelligent algorithms to perform target positioning, environment perception, path planning, environment interaction, and other aspects related to driving vehicles.
The YOLOv5s-CBC model has superior road target detection performance on different datasets, with mAP above 83%. For the four types of detection targets, truck, pedestrian, and cyclist, the average accuracy of the model is greater than 86%. For different environments, such as sunny, rainy, and night, the average accuracy of the model in this paper is 86.6%, and it has been improved by 3.35%, 3.25%, and 4.20% relative to the original YOLOv5s algorithm, respectively.
As a basic module in the adaptation of intelligent networked vehicles to complex environments, environment perception is a prerequisite for the realization of intelligent driving path planning and decision control modules and is also a key module that directly affects the safety of intelligent driving in intelligent networked vehicles. The YOLOv5s-CBC model proposed in this paper better realizes the recognition and detection of different road targets in different environments, improves the accuracy of intelligent vehicles in acquiring various information in different environments, and can effectively increase the comfort and safety of driving.