Lexical co-occurrence network and semantic relation mining based on English corpus
Mar 17, 2025

About this article
Published Online: Mar 17, 2025
Received: Oct 25, 2024
Accepted: Feb 09, 2025
DOI: https://doi.org/10.2478/amns-2025-0209
Keywords
© 2025 Guimei Pan, published by Sciendo
This work is licensed under the Creative Commons Attribution 4.0 International License.
Figure 1.

Figure 2.
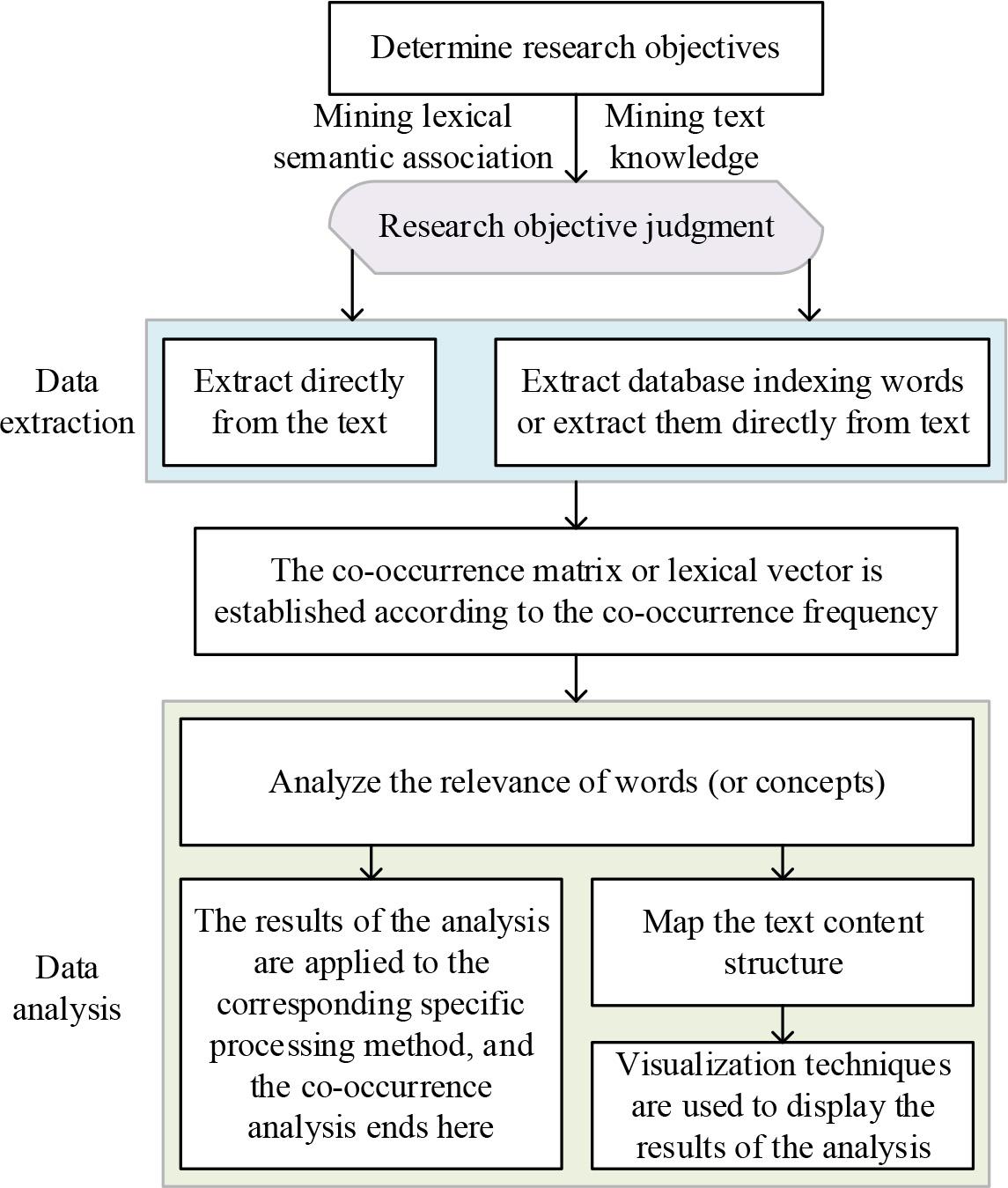
Figure 3.
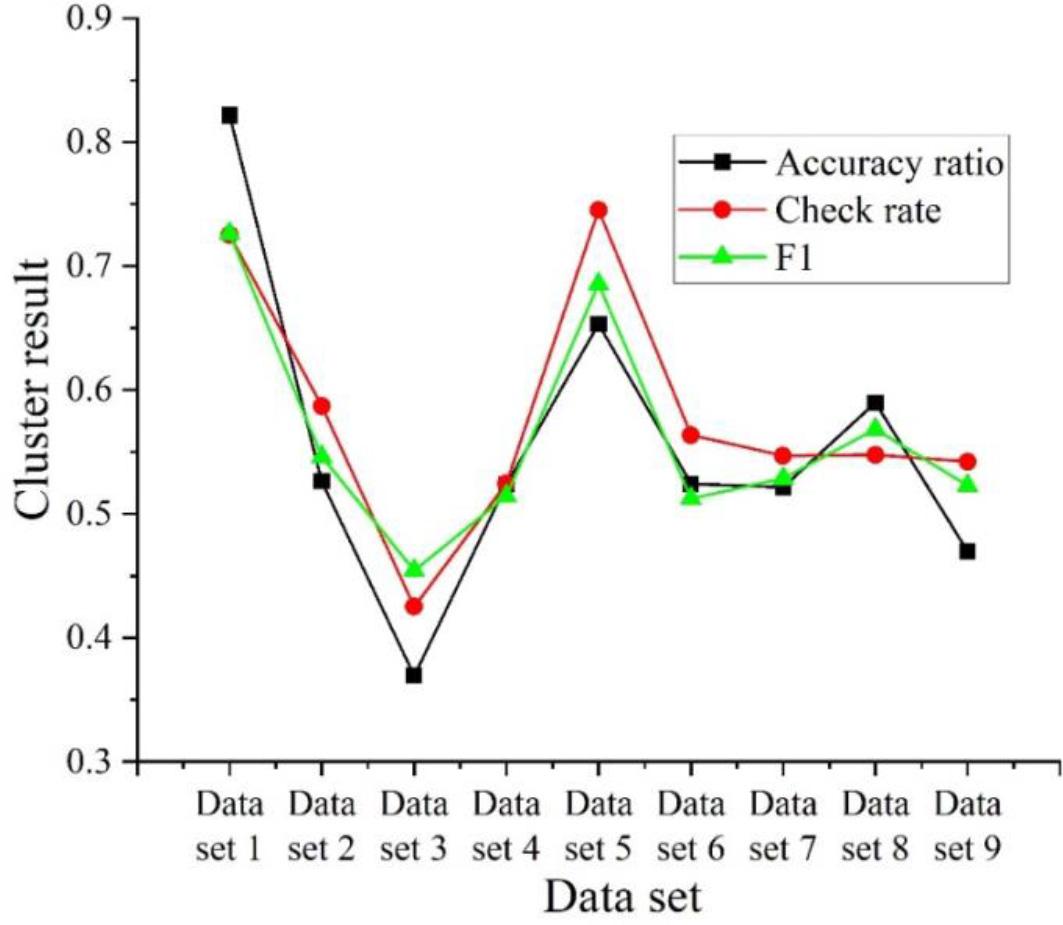
Figure 4.
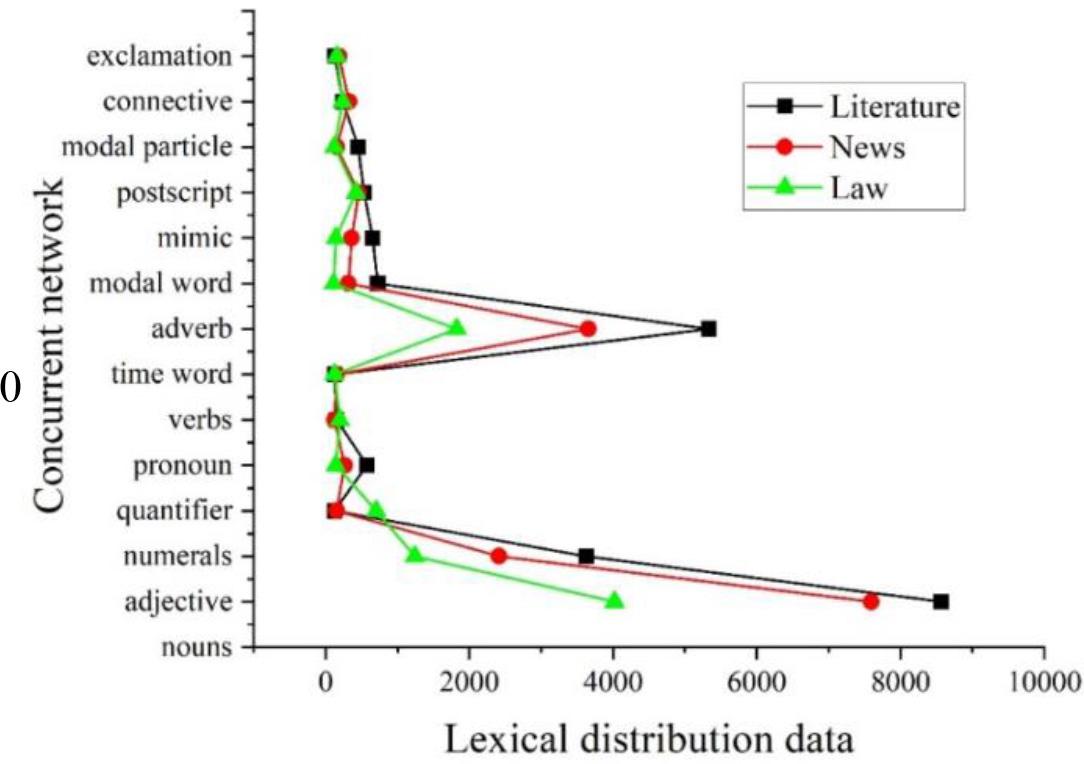
Some examples of artificial relevance in corpus
| Word A | Word B | Degree of correlation |
|---|---|---|
| Imperialism | Colonialism | 0.472 |
| Shampoo | Conditioner | 0.399 |
| Overseas Chinese | Settlers | 0.085 |
| Lion tiger | Tiger lion | 0.551 |
| Yongding River | Lugou Bridge | 0.364 |
| First order logic | Field of theory | 0.261 |
| The middle ages | Castle | 0.277 |
| Symphony | Movement | 0.211 |
| Taiwan | NT | 0.316 |
| Husband’s family | Wife’s family | 0.387 |
| Hewlett-Packard | Printer | 0.428 |
| Spring Festival | Dumplings | 0.395 |
Multi-path semantic correlation calculation results
| Characteristics of the correlation algorithm | Grade correlation coefficient |
|---|---|
| Separate use of the classification diagram | 0.42 |
| Reciprocal path | 0.23 |
| Depth information weighting | 0.39 |
| Information content weighting | 0.37 |
| Use the document map separately | 0.36 |
| A non-directional diagram of a two-way link | 0.25 |
| Link to link separately | 0.37 |
| Link to the link | 0.31 |
| Forward to the connection and adjust the weight of the parameters | 0.41( |
| Use the first paragraph instead of English | 0.33 |
| Integrated document and classification diagram, and adjust the parameters | 0.46( |
| Open test masking(WS353) | 0.37 |
Experimental parameter
| Parameter name | Parameter value |
|---|---|
| Maximum iteration number | 400 |
| Iteration out of the threshold | 0.003 |
| The single document extracts the number of keywords |
10 |
| Damping factor |
0.61 |
| Vertex score | 1.0 |
| Slide pane size |
2/6/10/15/20 |
Keyword extraction comparison
| Algorithm | Index | 2 | 6 | 10 | 15 | 20 | MEAN |
|---|---|---|---|---|---|---|---|
| TextRank | |||||||
| 0.3625 | 0.3212 | 0.3578 | 0.3755 | 0.3964 | 0.3627 | ||
| 0.4689 | 0.4968 | 0.4578 | 0.4772 | 0.4931 | 0.4788 | ||
| 0.3715 | 0.3251 | 0.3698 | 0.3745 | 0.3604 | 0.3603 | ||
| 53 | 56 | 59 | 52 | 51 | 54.2 | ||
| Improved textrank | |||||||
| 0.4596 | 0.4685 | 0.4725 | 0.4869 | 0.4911 | 0.4757 | ||
| 0.5521 | 0.5637 | 0.5417 | 0.5698 | 0.5927 | 0.5640 | ||
| 0.4122 | 0.4166 | 0.4867 | 0.4474 | 0.4516 | 0.4429 | ||
| 42 | 41 | 38 | 35 | 45 | 40.2 |
Number of data sets
| Classification | Text quantity | Classification | Text quantity |
|---|---|---|---|
| Data set 1 | 526 | Data set 6 | 64 |
| Data set 2 | 125 | Data set 7 | 153 |
| Data set 3 | 348 | Data set 8 | 186 |
| Data set 4 | 56 | Data set 9 | 54 |
| Data set 5 | 48 | - | - |