Personalized Analysis of Online Civic Education in Colleges and Universities with Improved Recommendation Algorithm

Publié en ligne: 17 mars 2025
Reçu: 11 oct. 2024
Accepté: 27 janv. 2025
DOI: https://doi.org/10.2478/amns-2025-0190
Mots clés
© 2025 Xingli Wang et al., published by Sciendo
This work is licensed under the Creative Commons Attribution 4.0 International License.
In the context of the wide application of algorithmic recommendation technology, its combination with the network ideological education in colleges and universities is both a general trend and an inevitable choice for injecting fresh blood into the development of ideological work under the new situation. In recent years, there are more and more achievements in the theoretical research of network ideological education in colleges and universities, and some achievements have been obtained, but in general, they are still relatively thin [1-3]. There are more researches on the method of network ideological education in colleges and universities, relatively scattered and unfocused researches on the problems and countermeasures of network ideological education in colleges and universities, and a relative lack of articles related to the summarization and enhancement of the experience of network ideological education in practice research [4-5]. Therefore, it is necessary to base on the current situation of network civic education in colleges and universities, and deeply analyze the reality of network civic education in colleges and universities. Fundamentally analyze and grasp the laws and characteristics of network civic education in colleges and universities, and put forward targeted suggestions and guiding opinions [6-7]. Improve the level of network expertise and educators’ network use in college and university civic education, continuously collect and expand the teaching resources of civic education, and strengthen the connotation construction of network civic education, which not only enriches the content of network civic education in colleges and universities, perfects the system of civic education in colleges and universities, promotes the development and construction of this discipline, but also has important theoretical references and guiding significance for the advancement of network civic education in Chinese colleges and universities[8-10]. With the gradual development of networking and data in the field of education in China, most of the disciplines have realized the transformation of the traditional teaching methods and educational modes, which has greatly improved the students’ learning interests and promoted the comprehensive completion of the teaching objectives [11-13]. In the network civic education in colleges and universities, the application of improved recommendation algorithms can not only transform the traditional civic teaching methods and achieve the teaching goal of civic moral education, but also comprehensively improve the quality of network civic teaching in colleges and universities, meet the personalized development of students, improve the construction of data-based network civic education in colleges and universities, and cultivate brand-new comprehensive talents for colleges and universities [14-17].
In this paper, a collaborative filtering recommendation algorithm based on the popularity correction factor is firstly proposed, on this basis, it is fused with the confidence course recommendation model based on user feature weights, and a hybrid recommendation algorithm based on the improved algorithm weighting is obtained. Firstly, the popularity correction factor is proposed, and the corresponding popularity value is used to determine whether to correct this item or not, and then the recommendation algorithm that integrates user feature interaction is proposed, the core of which lies in the use of user feature matrix instead of user rating matrix, and the user rating data is deeply mined, and this model proposes the numerical similarity of integrating the rating structural weighting factor as well as the quantitative structural weighting factor based on the normalized scoring criterion calculation method. At the same time, the system quality is also introduced to exact the numerical similarity. Ultimately, the fusion of the two similarity calculations is used to obtain the user similarity calculation as a result for efficient personalized recommendations of Civic and Political Education courses.
Recommendation algorithms are the most core technology in the recommendation system, which have a crucial impact on the effectiveness of recommendations.Mainstream generally divides recommendation algorithms into three categories: content-based recommendation algorithms, collaborative filtering-based recommendation algorithms, and hybrid recommendation algorithms. Content-based recommendation algorithms are recommended by analyzing the user’s past preferred items and generating items similar to them. Collaborative filtering-based recommendation algorithms analyze the similarity of users through data and then suggest similar preferences to similar users.Hybrid recommendation algorithms combine content-based recommendation algorithms with collaborative filtering, and may also incorporate technical approaches from other domains to generate recommended content.The algorithm learns from or operates on the data to make suggestions or decisions on behalf of the user.The user then interacts with the recommendations made by the algorithm, from which the algorithm generates the next generation of data for the algorithm.The underlying data used to train algorithms, the algorithms, and the way users interact with them have all changed dramatically over the past decade or so.These changes are both driving the era of algorithmic recommendations and revealing the essential characteristics of the algorithmic recommendation era.
With the advent of the era of algorithmic recommendation, individuals, groups and organizations have begun to enter the digital world woven by algorithms, and profound changes have occurred in the mode of production, consumption and learning of society. As a compulsory public course for all college students, the Civics and Political Science Class in colleges and universities undertakes the tasks of spreading Marxist theory, strengthening value leadership, and maintaining national ideological security. Therefore, to seriously analyze the impact of algorithms on the ideology and politics courses in colleges and universities, to actively play the institutional advantages of ideological and political education, and to improve the teachers’ and students’ understanding of algorithms are the essentials of the times for the ideology and politics courses in colleges and universities to abide by the correctness and innovation.
In recent years, algorithms have been increasingly applied to education and teaching in colleges and universities, providing unprecedented opportunities for large-scale understanding of learner behavior and internal characteristics. By introducing algorithms and data into information finding, recommender system provides new methods and injects new vitality into the teaching of Civics and Politics classes in colleges and universities, which makes some work relying on a large amount of data processing to be further developed, and promotes the change of the ecology of education in colleges and universities. The positive role of algorithms for the Civics and Political Science class in colleges and universities can be manifested in at least the following three aspects:
First, promote the precision of education and teaching. With the gradual acceleration of the pace of information technology construction in colleges and universities, most colleges and universities have introduced network-based educational management information systems. These systems have generated a large amount of data after a long period of operation, and algorithms can provide technical support for colleges and universities to explore new teaching modes and methods and construct a new ecology of teaching activities by analyzing these data.
Secondly, it is convenient to access the information. In the process of searching for information, the algorithm can help teachers and students in colleges and universities to conveniently filter information related to research from the massive information on the Internet, reducing the difficulty of collecting information.
Thirdly, to satisfy the need for specialized reading. The traditional library information service mainly focuses on the borrower’s information query by inputting certain query conditions, and the borrowing effect is relatively limited, but the algorithm can calculate the data according to the borrower’s daily reading habits and literature search records, provide the borrower with accurate and proactive information about the books that they may be interested in, and improve the borrower’s satisfaction and reading interest.
In this chapter, the collaborative filtering recommendation algorithm based on the popularity correction factor is fused with the confidence course recommendation model based on user feature weights [18] to get the hybrid recommendation algorithm based on the improved algorithm weighting, which better overcomes some of the problems of traditional recommendation algorithms.
The ratio of the number of users who have rated an item in a certain number of item set
Where
The traditional collaborative filtering algorithm overly relies on the rating value of the item that the users have had a rating record together [19], without paying attention to the size of the popularity of this item, resulting in a low accuracy of the final recommendation results, which is due to the fact that the similarity between the users is not taken into account in the calculation of the item popularity, which is an important factor. Take the example of students choosing the Civics program in colleges and universities. For example, if both students have chosen some kind of Civics education course, this does not mean that the Civics education courses that the users are interested in are similar to each other, this may be because this course is a mandatory course and most students have to choose this course to complete the mandatory credits, and it cannot be considered that the degree of similarity between the users is relatively high. If both students chose a course that is related to Civic Education, but non-required, then it can be assumed that both students are interested in similar content, and this is because only students who are interested in Civic Education will choose this course. So when calculating the similarity between users must consider the influence of cold items on it, some users make feedback on popular items this behavior does not fully reflect the difference between users, if you want to further explore the user’s favorite preferences, you can pay attention to the user’s feedback behavior on niche items. Therefore, the concept of popularity correction factor is proposed, this formula is not to correct all the items, but through the corresponding popular threshold to determine whether to correct this item, the formula is shown in equation (2):
In the formula,
Based on the Pearson similarity calculation formula, the popularity correction factor in formula (2) is introduced, and the improved formula is shown in equation (3):
Where
The core of the proposed recommendation algorithm incorporating user feature interaction is to use the user feature matrix to replace the user rating matrix, so as to provide users with more accurate recommendations for Civic Education courses. At the same time, in order to achieve more accurate personalized recommendation, it is proposed to deeply mine the user rating data, and improve the similarity calculation and rating prediction calculation. The model analyzes the relevant data and proposes a numerical similarity calculation method that integrates the rating structure weight factor and the quantity structure weight factor based on the normalized rating criteria.Also, system quality is introduced to ensure numerical similarity. Ultimately, the fusion of the two similarity calculations is utilized to obtain the user similarity calculation as a result for the recommendation of the Civic Education course. For the cold start barrier for new users, the lack of rating data causes the model to be unable to complete the personalized recommendation, based on this, the rating prediction rule is improved to overcome the cold start problem.
Structural similarity
Jaccard’s similarity is a statistical measure of similarity and difference between two finite sample sets. Specifically, it is calculated by comparing the size of the intersection of two sets with the size of the concatenation. The larger the value of Jaccard number [20], the more similar the two sets are.However, it does not use rating information in the calculation process, which makes the overlap between users higher. So in this paper, the rating information is fused into the similarity coefficient to solve this problem. The structural similarity
where
Numerical similarity
Numerical similarity refers to comparing the degree of similarity between two or more numerical values. In data analysis and machine learning, numerical similarity is an important concept to measure the proximity or relationship between data points.
In order to precise the numerical similarity, the scoring structure weight factor is added in this paper.
where
Meanwhile, the quantity structure weight factor optimization is introduced, where
System quality is an important factor in user ratings. The coefficient of dispersion is a statistical quantity used to measure the degree of dispersion of values in a data set. Expressed by the formula: Dispersion coefficient = standard deviation/mean, the smaller the dispersion coefficient, the lower the degree of dispersion of the data, i.e., the smaller the difference between data points, and vice versa. For systems with large rating dispersion coefficients, the differences in user ratings are significant, and the quality of the system has less influence in the similarity calculation. On the contrary, user ratings for systems with small rating dispersion coefficients are more consistent and are more likely to be influenced by system quality.To reduce interference with system quality, the discrete coefficient is used to optimize numerical similarity. The formula is as follows:
System popularity also plays an important role in numerical similarity calculation. Therefore, it is proposed to introduce a system popularity penalty factor to optimize the calculation of user similarity, in order to more accurately reflect the degree of similarity of interest in different Civic Education courses among users. For system
where
Finally, the structural similarity is fused with the numerical similarity, calculated as shown below:
Since the algorithm cannot effectively solve the cold-start problem, a method to improve the rating prediction rule is proposed to ensure that cold-start users can also get recommendations for personalized Civic Education courses. When a cold-start user logs in,
Experimental comparisons are conducted for the dataset of ideological and political disciplines in colleges and universities to verify the timeliness and feasibility of the improved recommendation algorithm in this paper and the recommendation algorithm based on graph neural network. The calculation of the loss function is carried out under the conditions of keeping the two algorithms in the word embedding are 100 dimensions, the learning rate is 0.01, the correction interval is 1.0, the soft constraint weights are 1.0 and the L1 regularization is used to prevent the Loss value from being minimized. During 600 rounds of training on the training set, both algorithms calculate the loss value by random sampling and adjusting the ternary, and record the final loss value through the line graph, and the final loss is shown in Fig. 1. From the performance of the two algorithms in the loss value function, it can be seen that with the increase of training rounds, the loss value of the two algorithms converge to similar values, both converge to 1000, thus indicating that the two are basically the same ability in the course recommendation, which proves the feasibility of this paper’s improved recommendation algorithms in the recommendation of Civics courses.
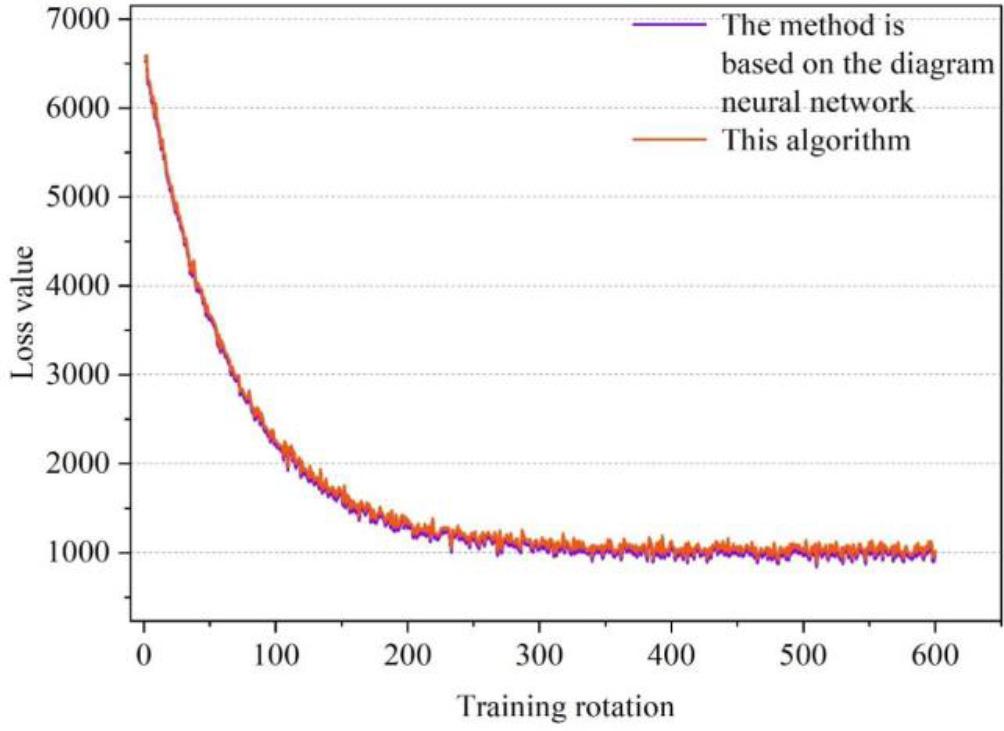
Comparison of loss values
The comparison is made by recording the duration of each Batch training, and the comparison results are shown in Fig. 2. According to the line graph of the time-consuming record, it can be seen that the average time consumed by each Batch of the improved recommendation algorithm in this paper is about 1.20 s, and that of the graph neural network-based recommendation algorithm is 1.30 s. It can be found that, due to the random initialization of the graph neural network-based recommendation algorithm, it prolongs the training process of local sampling data in the training process, and the training time is relatively long in the whole training process. In the same case, the improved recommendation algorithm in this paper, because of the combination of user characteristics in the initialization of the relationship, the results of the relationship initialization are closer to the actual, shorten the training time, and improve the efficiency of the Civics course recommendation.
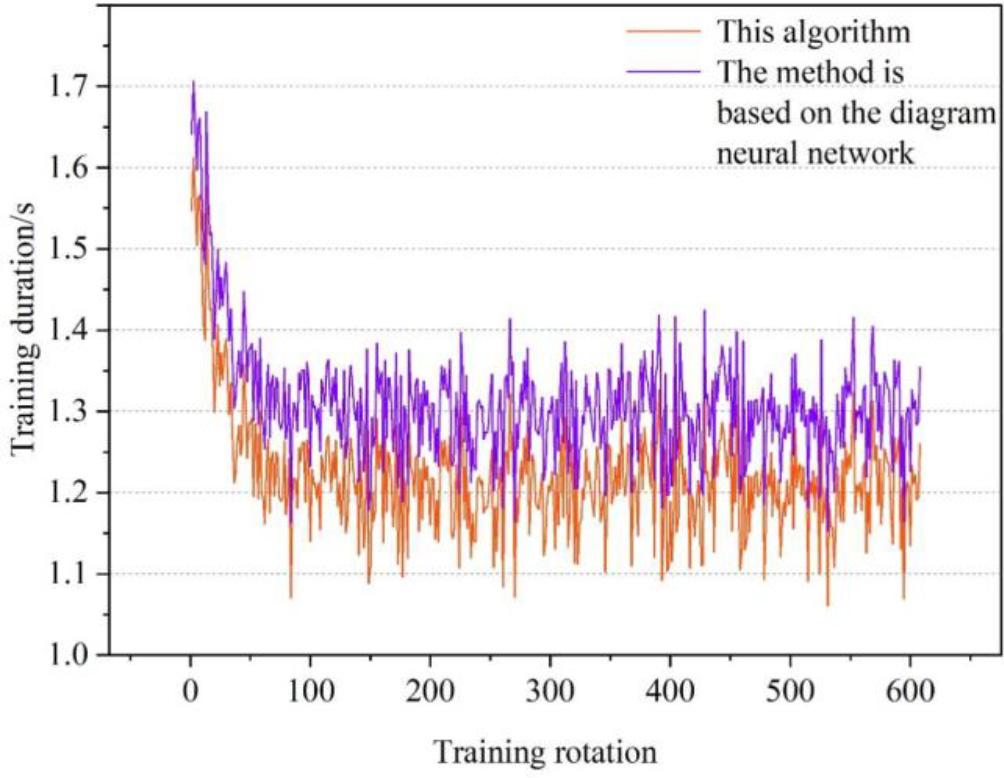
The algorithm takes a time comparison diagram
This case is designed according to the personalized learning model of Civic Education in colleges and universities supported by hybrid recommendation algorithms based on improved algorithmic weighting, and is implemented as a case study in a freshman Civic Education class, and one class is selected as a case study for demonstration. The research object selected by the author is the first-year students of a university, and two classes of comparable size, Class 2 and Class 3, are selected. Class 2 is used as an experimental class and class 3 as a control class, with the same teachers in both classes, and the pre-experimental investigation of the two classes in the last six months showed very little difference in grades, eliminating the interference of teachers and grades. Teachers use the smart classroom based on hybrid recommendation algorithm with improved algorithm weighting to teach in class 2, and class 2 adopts the traditional teaching mode, which is tested once before the experiment and once after the experiment. Finally, the effect of this model is tested by comparing and analyzing the results of two exams in two classes and classroom observation of students in the experimental class.
In order to compare and analyze the effect of personalized learning practice in Civics education supported by hybrid recommendation algorithm based on improved algorithmic weighting, the two scores of students in the two classes of the experimental class and the control class (one for the pre-experimental test score and one for the post-experimental test score) are compared and analyzed, and the two exams are different in content but comparable in difficulty. Class 2 is taught in personalized learning mode and is considered an experimental class.Class 3 is taught in the traditional manner and is considered the control class.Class 3 was given traditional instruction and was designated as the control class. At the end of the test, an independent samples t-test was performed on both scores of both classes using the data analysis tool IBMSPSS Statistics 25.0.
To conduct an independent samples t-test on the scores of the two classes, it is first necessary to check whether the scores of the two classes conform to a normal distribution. Using the one-sample K-S test in the nonparametric test in SPSS to analyze the achievement data of the two classes respectively, the results of the preexperimental K-S test are shown in Table 1, and the asymptotic significance (two-tailed) is 0.198>0.05, so the one-sample K-S test of the two classes conforms to the normal distribution. The superscript numbers a, b, c, and d in the table mean: a. the test distribution is normal, b. calculated from the data, c. Riley’s significance correction, and d. this is the lower limit of true significance.
| The single sample,kormogoov,was tested | |||
|---|---|---|---|
| Laboratory class | Cross-reference class | ||
| Student quantity | 35 | 35 | |
| Normal parameter a,b | Mean value | 83.23 | 83.56 |
| Standard deviation | 4.231 | 4.079 | |
| Extreme difference | Absolute | 0.116 | 0.114 |
| Positive | 0.062 | 0.057 | |
| Negative | -0.116 | -0.114 | |
| Inspection statistics | 0.116 | 0.114 | |
| Asymptotically significant (double tail) | 0.198 c,d | 0.198 c,d | |
Table 2 shows the analysis of the results of the independent samples t-test for the grades of the experimental and control classes, as can be seen in Table 2, in the traditional teaching, the average grade on the pre-test of the experimental class (class 2) was 83.23, and the average grade on the pre-test of the control class (class 2) was 83.56, which was slightly higher than the average grade of the experimental class by 0.33 points. The two groups’ scores were analyzed using the independent samples t-test, and as can be seen from the data in Table 2, the Levine’s test of equivalence of variances P=0.879>0.05 indicates that there is no significant difference in the sample variance of these two groups of data, i.e., the sample variance of the two classes is chi-square. The mean equivalence t-test Sig (two-tailed) = 0.708 > 0.05 indicates that there is no significant difference in the pre-experimental test scores of these two classes.
| Group statistics | |||
|---|---|---|---|
| Class | 2 | 3 | |
| Student quantity | 35 | 35 | |
| Mean value | 83.23 | 83.56 | |
| Standard deviation | 4.231 | 4.079 | |
| Standard error mean | 0.956 | 0.953 | |
| Independent sample inspection | |||
| Grade | |||
| Assumed equal variance | Unassuming equal variance | ||
| Levin variance equivalence test | F | 0.026 | |
| Significance | 0.879 | ||
| Average equivalent t test | t | -0.359 | -0.361 |
| Freedom | 62.135 | 61.453 | |
| Sig. (Double tail) | 0.708 | 0.708 | |
| Mean difference | -0.468 | -0.468 | |
| Standard error difference | 1.356 | 1.357 | |
| The difference is 95% of the confidence interval | -3.177 | 2.158 | |
| The difference is 95% true interval limit | --3.176 | 2.154 | |
Table 3 shows the results of the K-S test of the two classes’ scores after the experiment, from which it can be seen that the two classes’ scores on the post-experimental exams passed the SPSS nonparametric test, with asymptotic significance (two-tailed) of 0.089 and 0.201, respectively, which were both greater than 0.05, so that the one-sample K-S test of the two classes conformed to a normal distribution.
| The single sample,kormogoov,was tested | |||
|---|---|---|---|
| Laboratory class | Cross-reference class | ||
| Student quantity | 35 | 35 | |
| Normal parameter a,b | Mean value | 92.45 | 83.59 |
| Standard deviation | 5.423 | 4.096 | |
| Extreme difference | Absolute | 0.144 | 0.108 |
| Positive | 0.144 | 0.108 | |
| Negative | -0.110 | -0.111 | |
| Inspection statistics | 0.144 | 0.108 | |
| Asymptotically significant (double tail) | 0.089 c,d | 0.201 c,d | |
Table 4 shows the analysis of independent samples t-test results of the experimental and control class scores after the experiment, from Table 4 we can see that after personalized learning through the hybrid recommendation algorithm based on improved algorithm weighting, the average score of the test in the experimental class (class 2) is 92.45, and the average score of the control class (class 3) is 83.59, and the average score of the experimental class is higher than the average score of the control class by 8.95 points. The results of the two groups were analyzed using the independent samples t-test, and from the data in the table we can see that the Levine’s test of equivalence of variances P=0.597>0.05, which indicates that there is no significant difference in the sample variance of the two groups of data, i.e., the sample variance of the two classes is chi-square. The mean equivalence t-test Sig (two-tailed) = 0.022<0.05 indicates that there is a significant difference in the test scores of these two classes after the experiment, which illustrates that personalized learning under the hybrid recommendation algorithm based on improved algorithmic weighting has a significant impact on improving the learning effect of students’ Civic and Political Education.
| Group statistics | |||
|---|---|---|---|
| Class | 2 | 3 | |
| Student quantity | 35 | 35 | |
| Mean value | 92.45 | 83.59 | |
| Standard deviation | 5.423 | 4.096 | |
| Standard error mean | 0.969 | 0.859 | |
| Independent sample inspection | |||
| Grade | |||
| Assumed equal variance | Unassuming equal variance | ||
| Levin variance equivalence test | F | 0.452 | |
| Significance | 0.597 | ||
| Average equivalent t test | t | 2.277 | 2.271 |
| Freedom | 60.021 | 57.097 | |
| Sig. (Double tail) | 0.022 | 0.023 | |
| Mean difference | 2.958 | 2.958 | |
| Standard error difference | 1.281 | 1.285 | |
| The difference is 95% of the confidence interval | 0.355 | 0.352 | |
| The difference is 95% true interval limit | 5.513 | 5.519 | |
In order to more comprehensively analyze the effect of students’ personalized learning after Civics education through the hybrid recommendation algorithm based on improved algorithm weighting, in addition to the questionnaire survey, the author also recorded and summarized the students’ classroom learning behaviors in the capacity of an observer, and the classroom learning behaviors scale is shown in Table 5, and the behavioral record summaries before the experiment are shown in Fig. 3, and the behavioral record summaries after the experiment are shown in Fig. 4, and through the results It can be found that students at all levels have made some progress in different aspects. For example, for the group of students in difficulty, the progress in the behavior of the Civic Education classroom is shown in the average score on the seven evaluation items from 55 to 75, with a score increase of 20 points. Before the experiment, they had poor independent learning ability, could not finish the pre-study questions on time, could not even read the words, had little motivation to learn English, were hardly interested in English, and were unwilling to interact with their classmates, discuss problems and so on. After the experiment, their confidence in English learning increased, and they were also able to concentrate on listening to lectures and interacting with teachers and students, their learning behaviors were more active, the classroom atmosphere was more active, and the effect of classroom teaching was really improved to a certain extent.
| Index number | Specific performance | Score (100 points/items) |
|---|---|---|
| 1 | Be able to study independently before class and actively finish the preview | |
| 2 | Participate in the interaction, team work, explore and help each other | |
| 3 | Classroom attention, positive thinking and interactive response | |
| 4 | Interested in English and like English | |
| 5 | After class, you will review the leak | |
| 6 | Motivate learning and be confident in English learning | |
| 7 | Follow the discipline, the classroom atmosphere is active, the order is good |
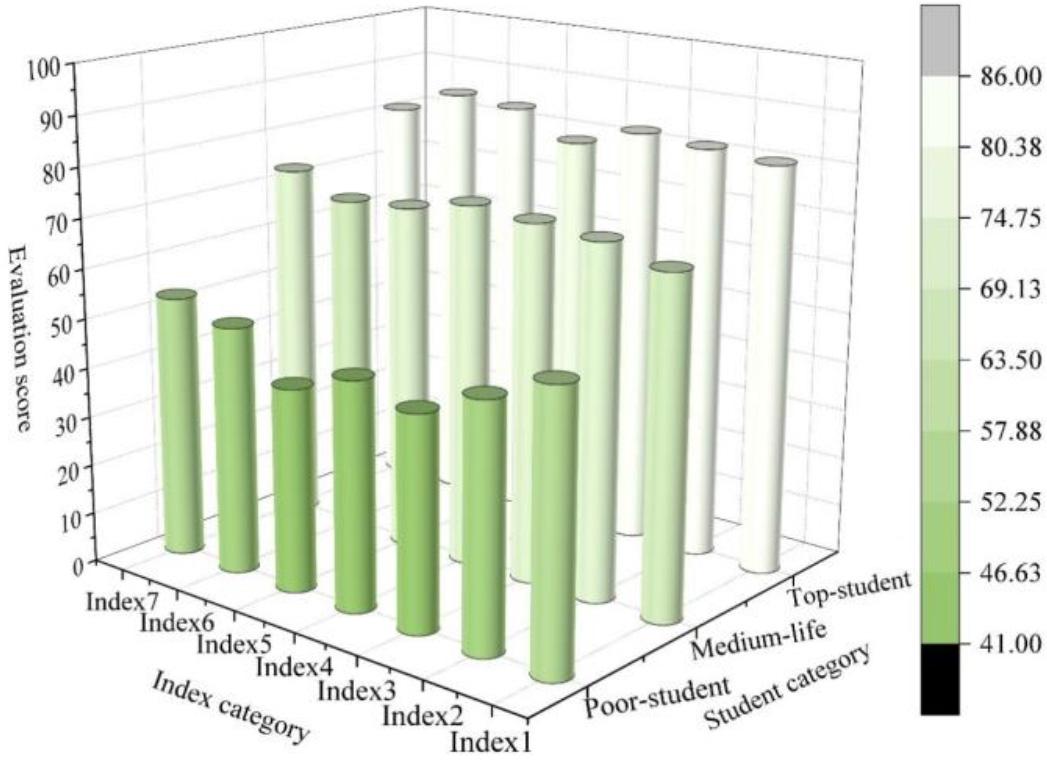
Pre-experiment student behavior scores
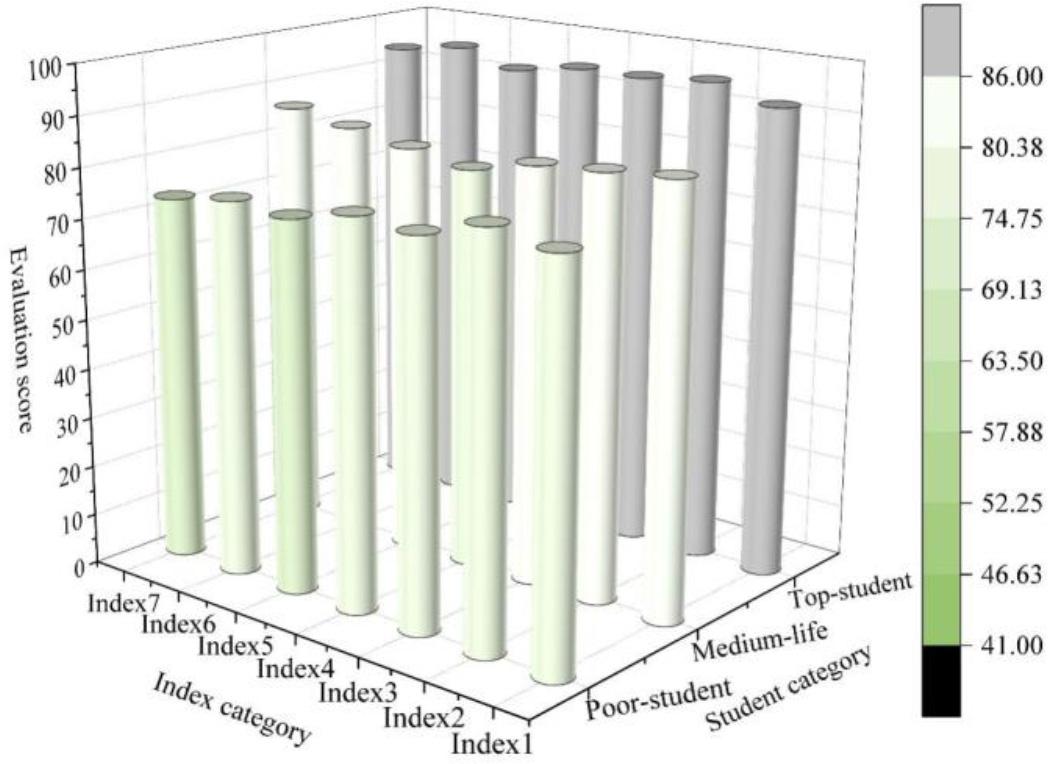
Experimental after-school behavioral scores
Personalized recommendation is one of the effective means of extracting specific information, for the lack of user features in the traditional recommendation method, a hybrid recommendation algorithm based on the weighting of user features is proposed to provide a personalized learning path for Civics education for college students.
With the increase of training rounds, the loss values of the improved recommendation algorithm and the comparison algorithm in this paper converge to a similar value of 1000, which indicates that both of them have the ability to recommend Civics courses. The average time consumed by the improved recommendation algorithm in this paper is about 1.20 s, which is 0.1 s less than the average time of the recommendation algorithm based on graph neural network.The improved recommendation algorithm in this paper shortens the training time and improves the efficiency of recommending Civics courses.
After personalized learning based on the hybrid recommendation algorithm weighted by the improved algorithm, the average score of the experimental class is 8.95 points higher than that of the control class. Mean equivalence t-test Sig (two-tailed) = 0.022, less than 0.05, indicating that there is a significant difference between the two groups’ test scores after the experiment, which proves that personalized learning under the hybrid recommendation algorithm weighted based on the improved algorithm is able to improve the learning effect of the students’ Civic and Political Education. All three types of students improved their behavior in the Civics education classroom. Struggling students’ average scores on the seven evaluation items improved by 20 points, indicating that the teaching effect of Civic and Political Education classroom has been improved to some extent under the implementation of the improved recommendation algorithm.