Research on English Corpus Construction and Optimisation of Language Teaching Strategies Supported by Data Mining Algorithms

Publié en ligne: 17 mars 2025
Reçu: 29 oct. 2024
Accepté: 12 févr. 2025
DOI: https://doi.org/10.2478/amns-2025-0179
Mots clés
© 2025 Hong Zhou, published by Sciendo
This work is licensed under the Creative Commons Attribution 4.0 International License.
English corpus is a concept that is more widely used in English linguistic research and is of great research value. The concept of English corpus is literally a storehouse of linguistic materials [1-2]. However, it is worth noting that the elements of the English language in the corpus are not stacked disorderly, but the information in the English language is arranged and combined according to reasonable and scientific standards and relevant laws, thus forming a corpus with great research significance and reference value [3-6]. In terms of data storage of English corpus, it mainly relies on the application of computer technology and database technology, that is, through the use of relevant technical means to realize the processing and conversion of the English language so as to include it in the database, which facilitates the application of English linguistics, and provides important data support and foundation for its research and development [7-10].
Language teaching strategies refer to the methods and means adopted to effectively promote students’ mastery and use of a certain language. It involves the role of the teacher, the selection and design of teaching materials, student participation and feedback mechanism. With the rapid development of society and the deepening of globalized communication, language teaching strategies have become more and more important [11-14]. In English teaching, teachers are required to optimize teaching strategies appropriately. In order to improve the effectiveness of English teaching, teachers can adopt various teaching methods with the help of modern teaching means and pay attention to the combination of theory and practice to stimulate students’ interest in learning so as to improve the effect of learning [15-17].
The prototype system of automatically constructing corpus in this paper utilizes a search engine system to collect relevant English teaching resources on the Internet using word2vec-based text data mining algorithms and extracts the content of the pre-processed English teaching resources as the initial corpus source, and then calculates the key core words of each category using relevant statistical methods. Then the keywords of each category are utilized to further collect rich English teaching resources related to each category, and the above process is repeated, and a set size of English corpus can be obtained after repeated iterations. Based on this, this paper proposes the application strategy of English teaching based on corpus, and carries out teaching practice with the assistance of corpus to explore the role of English teaching methods based on corpus on the improvement of English performance.
The main process and steps of automatically constructing the corpus are shown in Fig. 1. The prototype system utilizes a search engine system to collect webpages related to each category on the Internet and extracts the body content of these collected webpages as the initial source of the corpus, and then calculates the key core words of each category by using the relevant statistical methods. Then, the keywords of each category are utilized to further collect web pages related to each category, and the above process is repeated so that a corpus of a set size can be obtained through repeated iterations. The main process of the construction system is as follows Data collection phase collects theme-related web pages from the Internet and saves them in the initial web page dataset of the system.In the page cleaning phase, the web pages in the web data set are cleaned and processed. Since the encoding of web pages varies, it is necessary to standardize the encoding format of all web pages in advance and then transform all web pages into pages whose structure conforms to the specifications and relevant standards. The page parsing process utilizes the relevant knowledge to parse these standard web pages, filters out the irrelevant information, extracts the body information of the web pages, and saves the extracted body text information into the corpus. The lexical stage utilizes relevant lexical software to lexicalize the extracted web page text information and calculate the corresponding word and document frequencies.The category core word acquisition stage extracts the category core words of each category and then calculates the importance of the core words of each category and ranks them separately. In the scale control stage, the core words of each category and the corresponding category information are used to continue to collect web pages, and the above steps are iterated until the size of the corpus meets the set requirements. Corpus validity validation uses a variety of classification algorithms and test corpora to validate the validity of the corpus built by the system.

The main process of automatically building corpus
Since the dataset is the English corpus text obtained from crawling on the Internet, there will certainly be a lot of invalid data. This will have a significant negative impact on the experiments to be conducted later, so it is necessary to preprocess the English corpus text first.The preprocessing of data mainly involves cleaning the data and deleting some deactivated words. Data cleaning is the process of deleting or modifying some invalid or wrong characters in the data set so that the cleaned data can meet the requirements of later data analysis or mining. Obvious errors in the data set of numbers, characters, or symbols will be deleted from the text data set, and at the same time, those who are not in line with the norms and grammatical rules in the text of the power to modify the expression so that the data to be processed in the proportion of “dirty data” is greatly reduced for the next step in the preparation of data processing.
Word2Vec is intended to train and then characterize words as low-dimensional real-valued semantic vectors. Through the similarity measure between semantic vectors, the semantic similarity between the text can be calculated because, in the training process, the model and algorithm fully consider the syntax of the words and the combination of contextual consideration of the semantic information of the words, the training of the generated word query can be considered to be able to refer to the words and have rich semantic information.
The Word2Vec algorithm has two implementations: Continuous Bag of Words (CBOW) and Skip-gram.The specific principle of CBOW model training is to solve the probability of occurrence of the currently requested word according to its probability of occurrence in the context.Skip-gram, on the other hand, calculates the probability of occurrence of the context word based on the probability of occurrence of the current word. Both methods use artificial neural networks as their training algorithms, where each word is initialized as a random vector of dimensions, and after training, the algorithm obtains the optimal word vector for each word using the CBOW or Skip-gram method.
For simplicity, the following notation will be used in this paper to describe specific models or algorithms:
Let
CBOW does not have a hidden layer and the word vectors in the input layer use the sum or average of the word vectors in its context, and the output layer of the model is tree-structured.
The CBOW model takes the context
where
The output of the model’s output layer is most likely
A batch of new words were obtained, but they cannot be used as feature words or keywords in text in the electric power industry. In this part, the new words obtained will be used to process the English text corpus to be processed for word segmentation, and then a Word2Vec model will be trained, and the word vectors constructed by the Cbow algorithm in the Word2vec model will be utilized for the processing of clustering of the words, as it is a purely unsupervised algorithm, some non-specialized words will still be obtained despite of semantic clustering. As it is a purely unsupervised algorithm, some non-specialized words will be obtained in spite of the semantic clustering, so some filtering rules are handwritten to filter the words obtained from the clustering in the end.
Text data mining can take various forms, some of which involve extracting high-frequency words from text data and summarizing narrative statistics. There is a grouping of observations. The investigation is conducted to determine the tendency for two specific words to be used simultaneously in a set of sentences, and so on.All of these research methods are based on morpheme analysis. A morpheme is the smallest phonological combination in a language. Morpheme analysis is the process of separating morphemes from one sentence to another and analyzing which words are used in the sentence or correctly and which morphemes each sentence consists of in order to obtain basic statistics. In addition, keywords with a high degree of association are woven together to create an association network, which reveals the relationship between words and phrases and also comprehends the relationship between words and eras. In other words, it is possible to study to what extent the extracted keywords were paid attention to by Konosuke Matsushita himself in different periods, and how the different periods and keywords are related to each other.
In English teaching, the innovative application of English corpus can not only make students’ English learning more in-depth but also find a suitable way of English learning in the continuous exploration and ultimately increase their interest in English learning. First of all, one of the applications of English corpus in English teaching is to analyze the important and difficult points in teaching through the design and research of corpus and to help students solve various problems encountered in the process of English learning.
Under the background of the current development of information technology, the form of English teaching has gradually changed from the original completely “offline” teaching mode to a combination of “online” and “offline” teaching modes. The form of English teaching has gradually changed from the original completely “offline” teaching mode to the combination of “online” and “offline”. This “online + offline” teaching mode can not only make the original English teaching classroom richer but also can supplement some of the original classroom is not involved in the content of the systematic, digital teaching platform and the establishment of the corpus, the student’s interest in learning English greatly increased. The current application mode of English corpus in English teaching is mainly through the establishment of an English corpus education platform, which constantly enriches English teaching resources and provides students with a good classroom form.
Students utilize the English corpus to input their indistinguishable vocabulary into the platform’s search bar and then master the actual usage of the vocabulary by analyzing word meaning and usage. Vocabulary teaching with the help of corpus. Students are able to use the English corpus to identify and compare their shortcomings and differences, and to enhance their self-confidence in oral English communication, based on an understanding of the characteristics of spoken English. The application of English corpus in English teaching can give feedback on students’ learning, thus encouraging them to actively participate in the classroom, actively think about the questions, and use their answer ideas in the construction of English writing.
The objective of building an English corpus in China’s basic education stage has been clarified. Combined with the problems existing in the construction of the English corpus in China, it can be determined that the construction of the English corpus is based on improving the word level of the corpus, thus ensuring that the corpus can meet the needs of the practical application of English and theoretical research in China, and at the same time, it also has to satisfy the needs of English educators. Secondly, the construction of the English corpus in China needs to clarify the direction of its application, and the purpose should be clearly defined in order to determine the direction of the construction and structure of the corpus. Secondly, the scale of corpus construction should be reasonably determined in the light of the actual needs of corpus construction in China’s basic education stage, and it should be clarified whether the English corpus is an open system or not and whether the vocabulary and the scale of vocabulary should be included in the corpus and other kinds of information. Finally, the coverage of the English corpus in the basic education stage should be clarified. For the practical consideration of English education, it should try to include all the sources of English corpus that can be accessed on a daily basis, such as English textbooks, commonly used English, English videos, English newspapers and magazines, English broadcasts, English movies, English masterpieces, and so on.
With the continuous development of the times, intelligent corpus construction has become an important direction for corpus construction and development. The important form of corpus automation and intelligent construction has the function of real-time monitoring and intelligent updating, which can realize the automatic updating of corpus information, discovering new corpus, collecting new corpus and reporting new corpus through the network channel.
Building a school-based corpus, which includes a written expression corpus and an English listening corpus.The first contains corpora related to English writing and reading, such as English simulation composition. Under the environment of quality education, English teaching in the basic education stage emphasizes more and more on students’ speech teaching and listening teaching, so the school can organize the final oral examination to assess students’ English oral expression ability.
This study investigates the usage of appoint as a verb in real corpus using the English corpus constructed by the above method. Considering the various deformations of the word, the authors entered [appoint] in the BNC search box with the help of wildcard characters (which means searching for all forms of appoint, including appoint/appoints/ appointed/ appointed), and a total of 184 relevant corpus items appeared in the retrieval results. (appointed/ appointing). By analyzing the 184 retrieved corpora, we found that the commonly used high-frequency sentences about appointments are shown in Table 1. Through guided observation of the high-frequency sentence display, students can summarize the usage of appoint in real contexts: the frequency of the collocation of “Was appointed to/by/as” is the highest at 68. In conventional English vocabulary teaching, students can only learn the basic meanings and fixed collocations of appoint and make some sentences out of real context to consolidate what they have learned. The corpus can create a real situation so that students can make a lexical analysis of appoint by observing the sentences in real communication. That is, appoint is often used in passive sentence patterns in the past tense and the perfect tense, which means that the subject has been appointed to a certain position, emphasizing that the act of appointment has already taken place.
| No. | Typical period | Frequency |
|---|---|---|
| 1 | Was appointed to/by/as | 68 |
| 2 | Sb appointed position/sb appointed name as | 34 |
| 3 | Have/has been appointed to/by/as/for | 28 |
| 4 | Should/shall/will/may/can be appointd | 14 |
| 5 | Has/had appointed sb as | 10 |
| 6 | Appointed attributive | 30 |
The corpus can save the text first, and the example sentences that interfere with the lexical meaning of the keywords show the function of special usage, and those that are not very helpful in contouring the lexical meaning can be eliminated. Getting rid of redundant example sentences can effectively improve students’ vocabulary learning efficiency.
As shown in Figure 2, there are 11 collocations related to being addicted with a frequency of more than or equal to 3 times, of which 0 show positive semantics and 8 negative semantics with a frequency of 43 times, which are drugs/alcohol/cocaine/valium/nicotine/gambling/heroin/danger. There are 3 neutral semantic words with a frequency of 20 times, which are them/computers/women. The phrase shows a clear pattern of use, i.e., when being addicted to is combined with a word that has a negative semantic meaning, although it has the meaning of “being attracted to”, it is more focused on expressing “being addicted to something”.
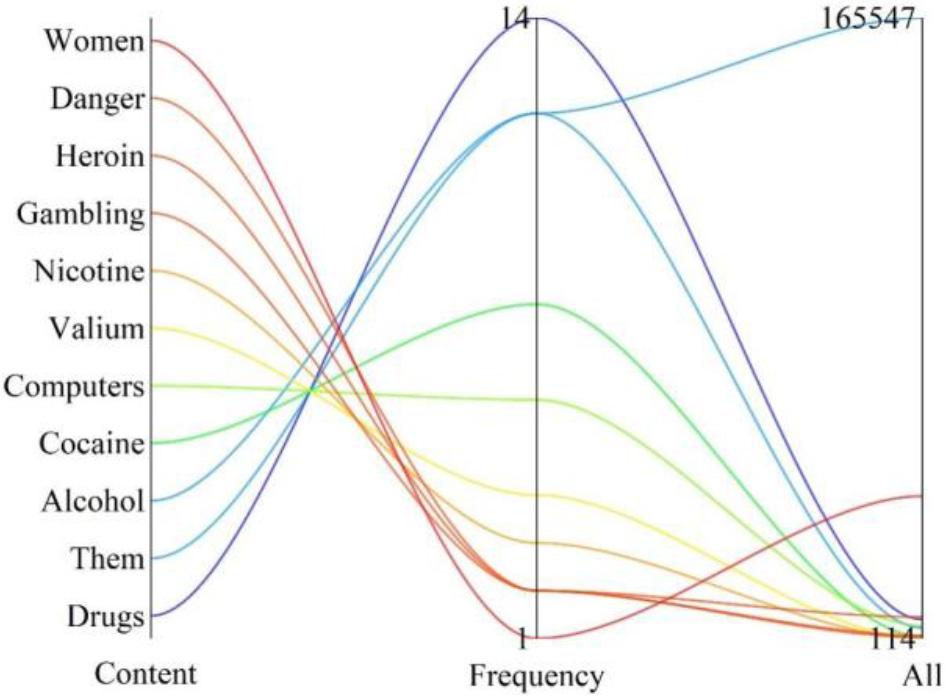
English collocation words
This study uses the theory of error analysis as its theoretical basis and analyzes the writing corpus of college students using the five steps of error analysis. Because of the large amount of textual material in the corpus, the corpus method is used to count and analyze the data of the corpus content so that, on the one hand, the common types of composition errors can be understood, and on the other hand, the probable causes of the errors can be analyzed according to the typical examples of errors. Eleven types of errors, totaling 18070, were found to exist in the corpus of college students. The distribution of the 11 types of errors is shown in Table 2. It is learned that among these speech errors, word form, syntax, vocabulary, verb phrases, and noun phrases account for the highest percentage of all errors. These five kinds of errors accounted for more than 90%, word form errors accounted for 26.57%, syntax errors accounted for 21.43%, vocabulary errors accounted for 19.45%, verb phrase errors accounted for 17.94%, and noun phrase errors accounted for 7.46%. Due to the huge amount of college students’ English composition corpus, with speech errors up to more than 20,000, it is impossible to present them one by one, so the five with the highest frequency of errors are now selected as examples to be elucidated. Through further investigation of writing errors, the reasons why college students make errors can be understood from the contextual context, and appropriate teaching suggestions can be made at the right time.
| Error type (marked symbol) | Number of errors in total (number) | The proportion of the errors |
|---|---|---|
| Etymology | 4802 | 26.57% |
| Verb phrase | 3241 | 17.94% |
| Noun phrase | 1348 | 7.46% |
| Pronoun | 334 | 1.85% |
| Adjective phrase | 92 | 0.51% |
| Adverb | 110 | 0.61% |
| Prepositional phrase | 223 | 1.23% |
| Conjunction | 42 | 0.23% |
| Vocabulary | 3514 | 19.45% |
| Collocation | 492 | 2.72% |
| Syntax | 3872 | 21.43% |
| Total | 18070 | 100% |
This study focuses on two ordinary parallel classes in the first year of college for English majors at S University, through a four-month experimental investigation as well as pre and post-test comparisons, and then completing the whole experimental study.
The investigation time of this study is from September to the end of December 2023, totaling nearly four months. In the early stage of the investigation, a large amount of relevant literature was reviewed, and a pre-test (i.e., a pre-survey related test on the research proposition) was conducted in September 2023 with 110 students from two classes. In the middle stage of the investigation (late September to mid-December 2023), the two classes in the experiment were compared (experimental class and control class), and relevant information and data were collected through communication with students, student interviews, and teacher interviews. In the late stage of the investigation (end of December 2023), the experiment ended with a post-experimental test of the two classes, thus completing this experimental study.
Before the beginning of the experiment, in order to better understand the students’ real English vocabulary learning situation as well as their ideas and attitudes towards English vocabulary learning, the questionnaire was prepared and distributed, and the data were recovered through the meticulous steps of interviewing and organizing previously. The author’s understanding of the current vocabulary learning situation of students is enhanced by the results processed by SPSS22.0 data software, which also provides valuable data for the author’s experimental design in the actual teaching application.The basic information section of the questionnaire contains two parts: gender and student’s English scores. The data results are shown in Table 3. The students who participated in this questionnaire are 110 students in the first year of the university, 52 male and 58 female. The ratio of the number of men and women is about 0.896, and the ratio of the total number of people accounted for 47.27% and 52.73%, respectively.
| Frequency | Percent | Valid percent | Cumulative percent | |
|---|---|---|---|---|
| Male | 52 | 47.27 | 47.27 | 47.27 |
| Female | 58 | 52.73 | 52.73 | 100 |
| Total | 110 | 100 | 100 |
The results of the data are shown in Table 4, so some students’ self-assessment data are not very accurate. The grades of the measurements were categorized into three grades: very good, average and bad. The data shows that 43.64% of the students think that their English performance is average, and 49.09% of the students think that their English performance is not good, which shows that a larger part of the students do not have confidence in their English learning, which leads to categorizing themselves as average and not good learners, while only 7.27% of the students think that their English performance is very good.
| Frequency | Percent | Valid percent | Cumulative percent | |
|---|---|---|---|---|
| Good | 8 | 7.27% | 7.27% | 7.27 |
| General | 48 | 43.64% | 43.64% | 50.91 |
| Bad | 54 | 49.09% | 49.09% | 100 |
| Total | 110 | 100% | 100% |
There were two classes, the experimental class and the control class, that participated in the pre-test exam, and both had 110 students. The mean of the pre-test exam scores of the experimental and control classes were 71.358 and 71.68, respectively. The comparison results are shown in Fig. 3. The test statistic of variance chi-square test F=0.004, Sig=0.963, according to the statistical guidelines of the F-test, Sig is greater than 0.05, variance chi-square, and probability of significance of the difference is P=0.702>0.05. Therefore, there is no significant difference in the pre-test. There is no significant difference between the performance of the students in the experimental and control classes in the exam. The means of the experimental and control classes were 80 and 72.4, respectively, with a mean difference of 0.322. There was a significant difference between the means of the two classes, and the performance of the experimental class was significantly higher than that of the control class. The variance chi-square test F-value is 0.211, Sig=0.652, variance chi-square, and the probability of significance of its difference is P=0.003<0.05. There were two classes, the experimental class and the control class, that participated in the pre-test exam, and both had 110 students. The mean pre-test exam scores of the experimental and control classes were 71.358 and 71.68, respectively. The comparison results are shown in Fig. 3. The test statistic of variance chi-square test F=0.004, Sig=0.963, according to the statistical guidelines of the F-test, Sig is greater than 0.05, variance chi-square, and probability of significance of the difference is P=0.702>0.05. Therefore, there is no significant difference in the pre-test. There was no significant difference between the performance of the students in the experimental and control classes on the exam. The means of the experimental and control classes were 80 and 72.4, respectively, with a mean difference of 0.322. There was a significant difference between the means of the two classes, and the performance of the experimental class was significantly higher than that of the control class. The variance chi-square test F-value is 0.211, Sig=0.652, variance chi-square, and the probability of significance of its difference is P=0.003<0.05. Therefore, there is a particularly significant difference between the post-test test scores of the two classes, and the post-test scores of the experimental class are significantly higher than those of the control class. In conclusion, after the experiment, both classes saw improvements in their post-test scores, but the improvement of the post-test scores in the experimental class using corpus vocabulary teaching was more significant than the improvement of the pre-test scores. This fully demonstrates the feasibility and necessity of the corpus teaching method in practice, which is more capable of improving students’ performance than the traditional mode and plays a great role in developing their comprehensive language ability.
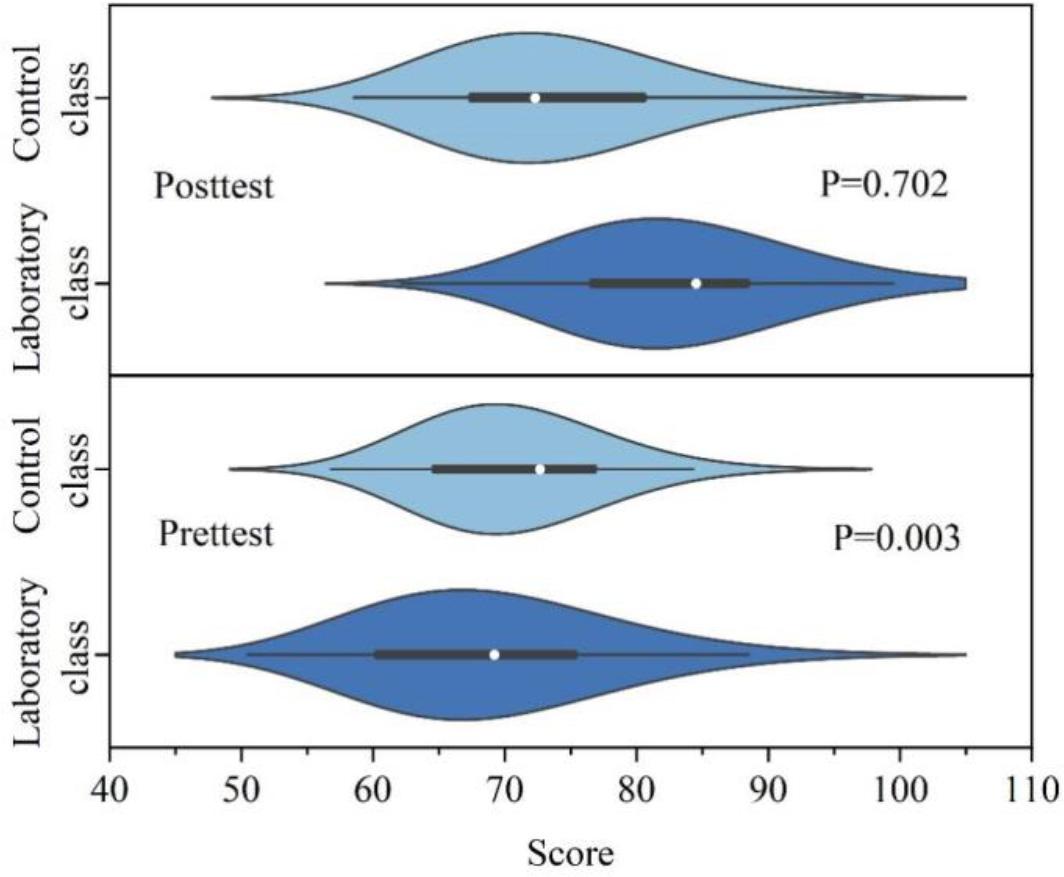
Test data and data analysis
In this paper, we use a word2vec-based text data mining algorithm to build a corpus system, crawl the English corpus text obtained from the Internet, calculate the keywords through data preprocessing, clustering, speed of speech analysis, and other methods, and use the keywords obtained to repeat the above steps until we build a certain size of the corpus. After the corpus practice teaching, it can be seen that the corpus can create real situations so that students can analyze the meaning of words and the collocation of words by observing the sentences in real communication. It can also identify common mistakes in college students’ English writing and provide appropriate teaching suggestions. Corpus vocabulary teaching can significantly improve the English performance of college students (P = 0.003).