Design of new energy market indicator system and dynamic risk assessment based on graph neural network: enhancing market monitoring and forecasting capability

Publié en ligne: 17 mars 2025
Reçu: 25 oct. 2024
Accepté: 04 févr. 2025
DOI: https://doi.org/10.2478/amns-2025-0165
Mots clés
© 2025 Xiaolu Wang et al., published by Sciendo
This work is licensed under the Creative Commons Attribution 4.0 International License.
The new energy index is an important index system to evaluate the energy structure and energy utilization of a country or region. With the continuous consumption of traditional energy and the increasingly serious environmental pollution, the development and utilization of new energy have become a common concern of all countries [1-4]. A new energy indicator is an important tool to assess the development and utilization of new energy, which can help us understand the development trend of new energy, optimize the energy structure, and improve the efficiency of energy use so as to achieve sustainable development [5-7]. New energy indicators include, but are not limited to, the proportion of new energy in the energy structure, new energy production capacity, new energy consumption, new energy power generation, new energy power installed capacity, and new energy power generation ratio [8-10].
First of all, the proportion of new energy in the energy structure is an important indicator to measure the transformation of the energy structure of a country or region. New energy includes renewable energy, such as solar energy, wind energy, hydroelectric energy, bioenergy, and clean energy, such as nuclear energy. Suppose the proportion of new energy in the energy structure of a country or region is high. In that case, it means that the country or region has made significant progress in energy transformation, less reliance on traditional energy sources, and cleaner and more sustainable energy utilization [11-14]. Secondly, new energy capacity and new energy consumption are important indicators to assess the level of new energy development and utilization. New energy production capacity refers to the total installed capacity of new energy equipment, reflecting the ability of a country or region to develop new energy. New energy consumption refers to the actual utilization of new energy in a country or region, which can reflect the utilization efficiency and consumption demand of new energy [15-17].
This paper analyzes the theory of risk spillover and the transmission path in the energy market, based on the mechanism of risk formation in the energy market. The risk measurement tool is used to empirically calculate the risk spillover between China’s carbon market and the new energy market. According to the factors affecting the price fluctuation of new energy, considering supply and demand, cost and economy, and combining the basic principles of the evaluation index system, we establish a new energy price fluctuation risk evaluation index system with supply and demand factors, economic factors, cost factors, and uncertainties as the first-level indicators. The daily data of WTI crude oil futures yield is used as sample data to compare model prediction results and verify the advantages of a graph neural network for new energy market risk warnings.
Marketization is the best method to optimize the allocation and utilization of energy resources. With the development of the world economy, especially the acceleration of the market-oriented reform process in the world, the world’s energy use is becoming more and more market-oriented, the world’s governments intervene directly in the use of energy more and less, the energy market has become the main mechanism for the formation of energy prices.
The energy market is the carrier of the economic operation of energy commodities, is the sum of energy commodity trading relations, and is the market economic system to deal with the energy problem of institutional arrangements [18-19]. This section analyzes the world’s energy market from three levels.
Energy end-consumption market;
Energy industry development market;
Energy derivative securities market.
Market structure refers to the basic characteristics of a market, including the number of vendors, the degree of homogeneity of the products of each vendor, and the ease of entry and exit from the market. In economics, there are typically four market structures. Monopolistically Competitive Markets, Oligopolistic Markets, Perfectly Competitive Markets, and Perfectly Monopolistic Markets. However, the international energy market has a complex market structure.
With the increase in membership, OPEC has developed into an international oil organization for some of the major oil-producing countries in Asia, Africa, and Latin America. With annual OPEC crude oil production accounting for 40 per cent of total global production and exports accounting for 55 per cent of the world’s total trading volume, it is clear that this is an oligopolistic market structure with a high rate of concentration. After nearly 40 years of development, OPEC has become an important force to be reckoned with in the international energy market. The complexity of the energy market structure is also reflected in the struggle between monopolies and non-monopolies.
Since the equilibrium price in the energy market has a continuous upward trend in the long run, it is determined that the real energy price must also have a long-term upward trend. In the short term, there are a variety of factors that affect the short-term trend of energy market prices.
Demand for oil in the global economy
Surplus production capacity
Climate political capacity
Refining capacity
Oil inventories
Development of alternative energy sources
Dollar exchange rate
Energy futures market speculation
The risk of price volatility in the energy market refers to the possibility of drastic, substantial, and unpredictable changes in prices. Energy market risk management research is usually directly applied to the methods and models based on financial markets, but in fact, the energy market risk has its special characteristics, and the traditional methods cannot fully meet the needs of energy market risk management.
The volatility of the market price represents the risk of the oil market, and the transaction represents the realization of the risk. In this link, the traders are essentially exchanging the use value of oil, along with the transfer of ownership of the physical commodity. In some cases, the transfer of ownership of energy assets does not occur, such as the storage and transportation process of oil also takes a long time, but the corresponding types of cost constraints of energy assets are always in a reasonable commercial process.
In view of this, this paper proposes a holistic definition of risk. By risk, we mean exposure to various risk elements, such as objective probability and time. “Objective probability” is the statistical significance of the likelihood of the outcome of the event, and “time” is the statistical significance of the evolution of things brought into the possibility of change. These two elements have universal, objective, and common characteristics. “Exposure” is the state of the subject of risk, which is localized, subjective and individual, depending on the subject of risk-taking. Objective probability and time constitute a kind of subjective probability space.
The transfer of information between financial markets can be seen as the impact of changes in one economy on other economies. With the deepening of the degree of information technology between markets, the speed of information transfer between the economies of the markets is also increasingly accelerated. In order to explore the correlation between the transfer of information between markets, many scholars have begun to use the term “spillover effect” to express the relationship between the transfer of information between markets. Therefore, the risk spillover effect can be expressed as follows: in the process of information transfer between different markets, when the asset price of a market is affected by the information changes, it further leads to other market asset prices also affected by the impact of the information and change. This cross-transmission of information between different markets is the risk spillover effect between markets.
Risk spillovers have four basic characteristics: negative contagion, negative externality, accumulation, and risk-return asymmetry.Contagion refers to the fact that when a risk arises in one market, it is transmitted from that market to other markets. Negative externalities refer to the corresponding spillover of risk through inter-market correlations when risk arises in one market and leads to the accumulation of market externalities. Accumulation refers to the further accumulation of risk, e.g., when the risk occurs in market X, causing sharp price fluctuations, it also causes price fluctuations in market Y, and price fluctuations in market Y, in turn, further affect market X, and so on, further accumulating inter-market risk. Markets generate different risk premiums in response to risk, creating operational risks and economic losses between them, which is known as risk-return asymmetry.
In the study of risk transmission in energy financial markets, risk transmission between the oil market and the stock market and exchange rate market is a complex process, which not only needs to take into account the characteristics of non-linearity, multi-timescale, and asymmetry of cross-market inter-risk transmission, but also it is crucial to choose the appropriate samples and methods to conduct the related research.
The research related to risk transmission in energy financial markets conducted in this paper mainly refers to the mutual transmission of risk between energy financial markets and major financial markets. It is worth noting that risk transmission in the context of the financial crisis is an integral part of risk transmission in energy financial markets, which means that risk transmission in energy financial markets includes risk transmission in the context of the financial crisis. The financial crisis is, to some extent, a product of the continuous accumulation of financial risks. The financial crisis stage is considered to be the outbreak stage of financial risks, and the risks after the outbreak continue to spread and spread to various markets, that is, the risk transmission stage of the financial crisis.
The energy financial market is a new type of trading market that is based on the integration of the energy and financial markets.The close connection between energy financial markets and traditional financial markets will only strengthen, not weaken.Energy financial markets are not only affected by risk spillovers from related markets, but they cannot avoid transmitting risks to other markets related to them.
In financial markets, risk measurement refers to the methods and tools used to measure the level of risk of an investment asset. It helps investors understand the risk level of an investment asset and helps them make more informed investment decisions. Commonly used risk measures include VaR and ES. The magnitude of the risk measure is a factor that investors must consider when making investment decisions. Risk measurement can help investors evaluate investment strategies and asset allocations, and reduce potential investment risks.
Value at Risk (VaR), VaR is a means of quantitatively assessing risk. Its formula is expressed as follows:
Expectation Shortfall (ES): ES indicates the average degree of loss suffered when the portfolio loss exceeds the VaR threshold. Its formula is expressed as in equation (2):
ES essentially calculates its conditional expectation for extreme values greater than VaR. By taking into account the mean level of the extremes on top of the VaR, it is more reflective of the risk characteristics of the portfolio or asset and is better suited to expressing tail risk.
Generalised Autoregressive Score (GAS) models are also known as dynamic conditional score models. This is because GAS models are able to capture the complexity and non-linear relationships in the time series, thus more accurately describing future trends. It provides a new option for modelling the volatility of financial asset returns.
Assuming
The probability density function can account for the fact that the observed information at moment
Among them:
The multivariate Student’s t-distribution, based on a mixture of multivariate normal and cardinal distributions, has a wider range of applications and greater flexibility, and compared with the multivariate normal distribution, it can better capture outliers, sharp peaks, thick tails and other features in the financial time series, which demonstrates its superiority. Let
In rolling estimation, using matrix
The estimation of dynamic correlation coefficients using the multivariate GAS model is similar to the generalised dynamic conditional correlation coefficient (DCC-GARCH) model. Assuming that the distribution is a multivariate student t-distribution for multidimensional when taking two random variables
Their correlation coefficients are calculated as follows:
The correlation coefficient
The final dynamic correlation coefficient based on the GAS model can be expressed as:
Conditional at-risk value (CoVaR), which measures the impact of subsystems on total system risk when they are in crisis. The
In the framework of the GAS model, the dynamic correlation coefficients have been calculated and, according to equation (13), the expressions for VaR and CoVaR can be written as equations (14) and (15), respectively:
The risk premium of system
Financial institutions can use Δ
In order to compare the risk spillover contribution of different systems to system
In this paper, the daily closing prices of carbon emissions trading in Shenzhen and Hubei are selected as representative products of China’s carbon market. The power coal industry index compiled by CITIC Securities Company is selected as a representative product of the coal market, and the daily closing price of the crude oil spot in Daqing is selected as a representative product of the crude oil market, and the coal market and the crude oil market are selected as representative products of the traditional energy market. The daily closing price of the CSI New Energy Index (399808) is selected as the representative product of the new energy market.Carbon market data and new energy market data are available from the Wind database, while traditional energy market data is available from the Choice database.The selected data sample interval is from January 8, 2015 to October 20, 2023.
The GARCH model can comprehensively portray the volatility of the yield series, thereby analysing the problems. The data has been tested to determine the existence of the ARCH effect in the yield series, so this paper uses the GARCH (1,1) model to test and analyse, effectively eliminating the conditional heteroskedasticity. The results of parameter estimation of the GARCH model are shown in Table 1, which shows the Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC). The AIC and BIC values of the new energy market are 3.9865 and 3.8714, respectively. And
The GARCH model parameter estimation result
| Shenzhen carbon market | Hubei carbon market | Coal market | Crude oil market | New energy market | |
| 0.0352 | -0.0351 | 0.0642 | 0.0724 | 0.0507 | |
| 1.8579 | 0.5628 | 0.0597 | 0.2458 | 0.0214 | |
| 0.3264 | 0.6587 | 0.0928 | 0.1468 | 0.0575 | |
| 0.6175 | 0.3051 | 0.8994 | 0.8325 | 0.9267 | |
| AIC | 7.6814 | 4.5007 | 3.6125 | 4.6119 | 3.9865 |
| BIC | 7.7789 | 4.1236 | 4.0437 | 4.7325 | 3.8714. |
The Ljung-Box Q test for the GARCH(1,1) model is shown in Table 2. The Ljung-Box Q test on the residual series of the GARCH(1,1) model aims to assess the presence of autocorrelation in the residuals of the model and thus, indirectly detect the presence of heteroskedasticity. The original hypothesis (H0) was the absence of autocorrelation in the residual series. The test results show that for all five return series, the statistics of the Ljung-Box Q test are greater than the critical value corresponding to the 1% significance level. The Ljung-Box Q-test p-value for the new energy market is 0.3641, and the p-values are all well above the 0.05 level of significance. This means that there is not enough evidence to reject the original hypothesis, leading to the conclusion that there is no significant autocorrelation in the residual series of the GARCH(1,1) model, suggesting that the model effectively eliminates heteroskedasticity.
The Ljung-Box Q test of the GARCH(1, 1) model
| Market | Ljung-Box | P VALUE |
| Shenzhen carbon market | 0.0067 | 0.9537 |
| Hubei carbon market | 1.2543 | 0.2856 |
| Coal market | 0.1895 | 0.6979 |
| Crude oil market | 0.9677 | 0.3508 |
| New energy market | 0.9568 | 0.3641 |
Combining the results of the Ljung-Box Q-test and other statistics (AIC, BIC, etc.), it can be concluded that the GARCH(1,1) model has good robustness. Therefore, the model is suitable for use in the calculation of Value at Risk (Va R) at a later stage and provides a reliable tool for financial risk management.
Fitting Copula function
The selection of the Copula function is shown in Table 3. According to the principle of maximum great likelihood value (LogLike) and minimum AIC and BIC, Gaussian Copula is selected as the optimal function for the Shenzhen carbon market and new energy market, with LogLike=0.52. Frank Copula is selected as the optimal function for the Hubei carbon market and new energy market, with AIC and BIC of 1.19 and 7.53 respectively, BIC are 1.19 and 7.53 respectively.
Selection of copula functions
Gaussion Copula
Student-t Copula
Frank Copula
Shenzhen → new energy
LogLike
0.52
1.08
0.25
AIC
0.91
2.31
1.68
BIC
7.04
15.27
8.34
Hubei → new energy
LogLike
0.25
-0.15
0.51
AIC
1.64
5.93
1.19
BIC
7.79
16.34
7.53
Measuring CoVaR
After the parameter estimation is completed, CoVaR, ΔCoVaR and %ΔCoVaR values are calculated, respectively. The risk spillover values between the carbon market and the new energy market are obtained, and the risk spillover values between the carbon market and the energy market in Shenzhen and Hubei (q=0.05) are shown in Table 4. The CoVaR value of Shenzhen’s carbon market and new energy market is -3.654.
Shenzhen, hubei carbon market and energy market risk spill value (q= 0.05)
CoVaR
ΔCoVaR
%ΔCoVaR
Shenzhen carbon market → new energy market
-3.654
0.379
8.76%
Hubei carbon market → new energy market
-3.245
0.197
6.35%
New energy market → shenzhen carbon market
-25.964
3.564
14.72%
New energy market → hubei carbon market
-4.012
0.758
16.34%
In order to simplify the risk spillover effect between the Chinese carbon market and the new energy market, a similar weighting calculation method between the Chinese carbon market and the traditional energy market is adopted to derive the risk spillover value between the Chinese carbon market and the new energy market, which can more accurately determine the risk level between the Chinese carbon market and the new energy market.
The risk spillover values (q=0.05) of the carbon market and energy market are shown in Table 5. According to the direction of the spillover, the spillover effect between the carbon market and the new energy market is a bidirectional spillover that also shows bidirectional characteristics, but the dynamics are different compared with the traditional energy market. The risk spillover from the new energy market to the carbon market (16.35 per cent) is significantly higher than the spillover from the carbon market to the new energy market (7.86 per cent). This phenomenon reflects the fact that, given the accelerated global transition to sustainable energy, turbulence in the new energy market is likely to have a more significant impact on the carbon market.
The risk spilt on the carbon market and energy markets (q= 0.05)
| CoVaR | ΔCoVaR | %ΔCoVaR | |
| Carbon markets, new energy markets | -3.596 | 0.348 | 7.86% |
| New energy market, carbon market | -13.078 | 2.053 | 16.35% |
In summary, it can be seen that, regardless of the direction of risk transmission, the risk spillover effect between the new energy market and the carbon market is smaller than that between the traditional energy market (e.g., coal and crude oil markets) and the carbon market. This phenomenon reveals an important substitution effect, i.e., with the development and application of new energy technologies, the new energy market is gradually replacing the traditional energy market, thus reducing the carbon market’s dependence on the traditional energy market. The existence of this substitution effect is reflected not only in quantitative indicators of risk spillover but also in changes in global energy consumption and investment trends.
Graph Neural Networks (GNN) extend the existing concept of neural networks for processing data represented in graph domains [20-21]. In a graph, each node is naturally defined by its features and associated nodes. The goal of a GNN is to learn the state embeddings
Let
Once the graph neural network structure is available, the next problem is how to train the parameters inside function
There are various variants of graph neural networks, but these variants can be integrated into the following three generic architectures of graph neural networks: message-passing neural networks, non-local neural networks and generic graph neural network architectures.
Message-passing neural Network (MPNN): A generalised framework for supervised learning of graphs. The MPNN framework abstracts commonalities between centralised graph-structured data models such as graph convolution, gated graph neural networks and non-graph spectra. The model contains two phases: the information transfer phase and the output phase. The information transfer phase goes through
This approach of computing the domain transfer information first in computing the updated state embedding is very general. The application of this architecture is presented here using gated graph neural networks as an example:
Non-local neural networks are proposed to capture long-term dependencies in neural networks. The non-local operation itself is an overview of the classical non-local operation notation applied to computer vision. The role of the non-local operator notation is to compute the response at a given location from the weighted total of the state embeddings of all nodes, the set of which can be distributed in time, temporal or spatio-temporal.
According to the definition of the non-local averaging operator, typically, the non-local computation can be defined by the following equation:
Gaussian relation: the Gaussian relation non-local calculator and the choice of function
Gaussian embedding: extending Gaussian relations to higher dimensional spaces through the idea of embedding, where
Point Multiplication: equation
Polymerisation:
Factors affecting the volatility of new energy prices are numerous and complex, and the study and analysis of factors affecting the volatility of new energy prices can effectively control the sources of risk in the new energy price market. Influencing factors can be divided into deterministic risk factors and uncertainty risk factors according to their frequency and whether they lead to the inevitable occurrence of risk.
In this paper, the study of new energy price volatility risk factors will also include deterministic and uncertainty factors. Deterministic risk factors are mainly divided into supply and demand factors, cost factors, and economic factors.
Supply and demand factors
Supply and demand is one of the basic factors affecting the price of commodities. New energy is a product of other commodities. Its price is also determined by its value. And fluctuations in the impact of supply and demand, while other factors are indirectly affected by supply and demand.
Cost factors
The cost factor is inherent in the intrinsic factors of commodities, but it is also one of the basic factors affecting the price fluctuations of commodities.The cost of energy prices is mainly composed of resource costs, production costs, transportation costs, and operating costs.
Economic factors
The impact of economic cycle factors on energy prices is mainly manifested in the fact that the speed of economic growth directly affects the social demand for energy consumption, which affects the price of energy, which in turn affects the profitability of the energy industry.
Uncertain risk factors are mainly divided into geopolitical factors, natural disaster factors, and national policy factors.
The appropriateness of the selection of evaluation indicators will affect the evaluation results to a greater or lesser extent. If there are more evaluation indicators, there will be duplications between indicators and cross-inclusive relationships between certain indicators, and if there are fewer evaluation indicators, they will not be representative, affecting the comprehensiveness of the results. There are many factors to be considered in evaluating the risk of volatility of China’s major energy prices, and these risk factors affect and constrain each other, so whether or not a scientific and reasonable evaluation indicator system can be established relates to whether or not it can play a role in the evaluation. In order to ensure that the evaluation index system has the expected effect, it is important to follow the following four basic principles when establishing it.
Scientific principle
Systematic principle
Applicability principle
Principle of Purposefulness
Following the above 4 principles, this paper adopts a comprehensive evaluation method for the risk of new energy price fluctuations, taking supply and demand factors, economic factors, cost factors, and uncertainty factors as a total of 4 risk factors as primary indicators. The corresponding 12 secondary indicators are selected as measurement variables to establish the new energy price volatility risk evaluation index system.
The new energy price fluctuation risk evaluation index system is shown in Figure 1. The supply and demand factors include energy storage and extraction ratio, energy supply and demand ratio, and external dependence on energy. Economic factors include industrial value added, GDP growth rate, and US dollar exchange rate. Cost factors include production costs, transportation costs, and safety costs.Uncertainty can be caused by emergencies, national policies, and natural disasters.
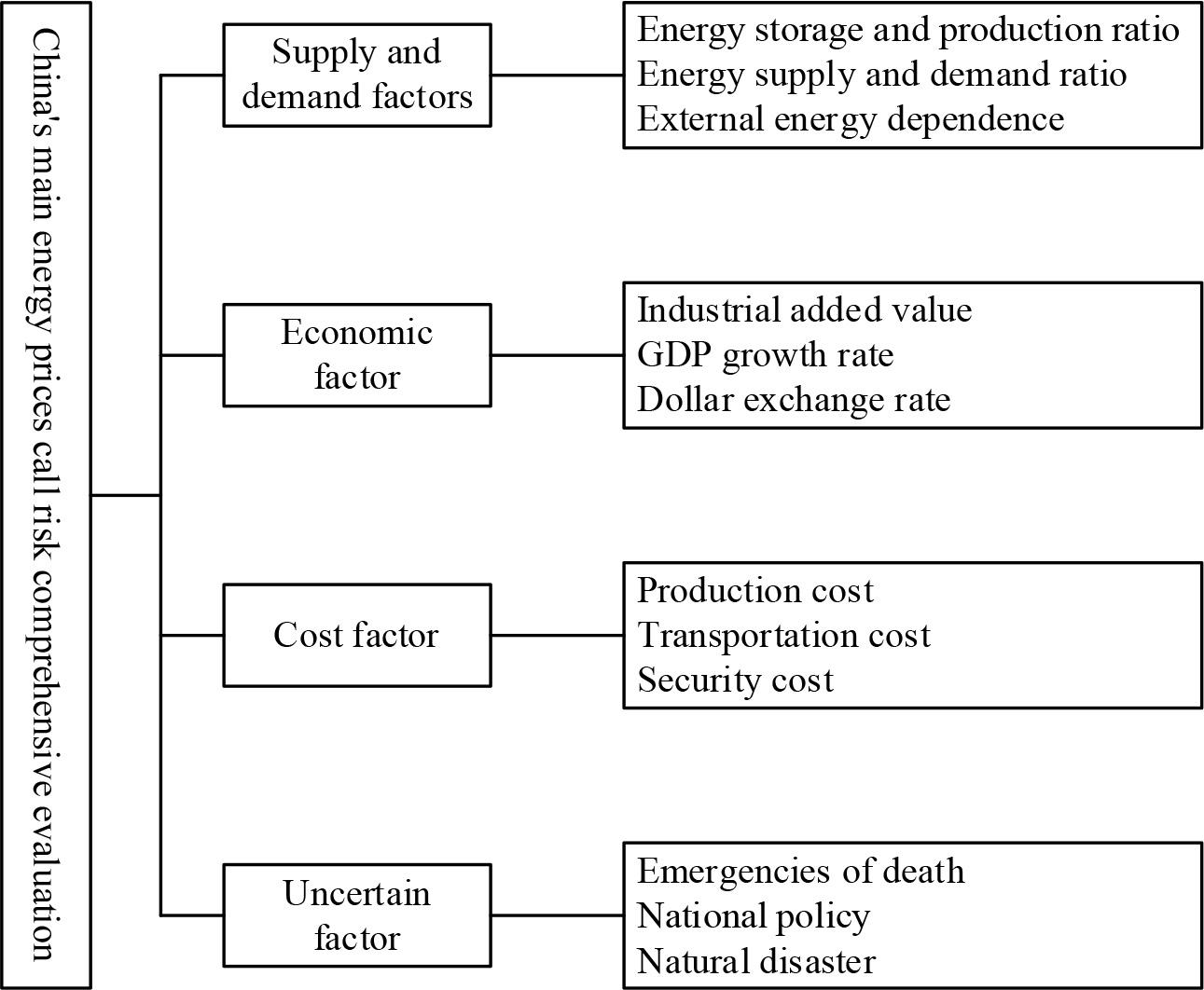
New energy price fluctuation risk evaluation index system
In this paper, nine indicators, namely COMEX gold, Euro RMB exchange rate, Yen RMB exchange rate, USDX US Dollar Index, WTI crude oil, Hong Kong Dollar to RMB exchange rate, US Dollar to Hong Kong Dollar, Pound Sterling to RMB exchange rate, and Shanghai Stock Exchange 50 Index, are finally selected as research objects. Since more data is needed for forecasting, this paper selects the daily closing prices of these nine indicators from 2015 to 2023 as the self-knowledge data for forecasting.These nine indicators are processed using upper and lower mean padding methods and descriptive statistics on risk.
In this paper, GRU units in graph convolutional neural networks and recurrent neural networks are used to forecast the nine financial indicators. The Pearson correlation coefficient between indicators is used to construct the graph structure in graph convolutional neural networks. For the Pearson correlation coefficient greater than 0.8, this paper considers that there is a correlation between the two variables, and the value of the element in the corresponding position of the neighbour matrix is 1. For the value of the Pearson coefficient less than 0.8, the value of the corresponding element of the neighbour matrix is 0. The calculation method of the elements of the neighbour matrix is shown below:
In order to better compare the prediction performance of this paper’s method on a variety of amount indicators, this paper chooses Long Short-Term Memory Neural Network (LSTM), Random Forest, and XGBoost to compare with this paper’s method. In this paper, the mean absolute error, mean absolute percentage error, and root mean square error are chosen as statistical indicators.
In this section, the energy stock price of GNN SSE 50 calculated by the GRU unit is used to predict the value of the next day by analyzing historical data from the previous 12 days.X is the input data, the number of rows is the number of financial indicators, and the number of columns is the number of input times.In this paper, 9 financial indicators are used to predict the value of the next point in time using the values of the previous 12 inches. Therefore, X is a matrix with 9 rows and 12 columns.
To better illustrate the excellent performance of the methods used in this paper, LSTM, Random forest, and XGBoost are used to compare with the methods in this paper. The GNN constructed in this paper uses 300 hidden units with a batch size of 64. The learning rate is 0.002 and the number of training times is 500. The LSTM used is a two-layer LSTM with a Dropout before the output layer to prevent overfitting. The Dropout Rate set is 0.5.
Random forest is an integrated algorithm that consists of multiple decision trees and no association between the decision trees that do not pass.Random forest is a commonly used machine learning model for both classification and regression problems. The number of Random Forest trees used in this paper is 30. XGBoost is also known as an extreme gradient boosting tree. It is an implementation of a boosting algorithm. The number of trees is 300, and the maximum depth is 6. In this paper, 95% of the data is used for training, and the remaining 85 samples are used as the test set.Table 6 displays the prediction errors of various methods for the SSE 50 index.
The prediction error of the Shanghai 50 index
| MAE | MAPE | RMSE | ||
| Shanghai Shanghai 50 index | GNN | 1.125036 | 0.000542 | 9.326473 |
| LSTM | 4.653381 | 0.001779 | 38.490865 | |
| Random forest | 1.560437 | 0.000459 | 14.527119 | |
| XGBoost | 0.983642 | 0.000406 | 8.667859 |
It can be seen that among several machine learning models, GNN achieves the highest prediction accuracy for stock prices, and its performance outperforms other models by at least 20%. Meanwhile, this paper also selects and replaces the parameters of various estimation methods and finds that none of them exceeds the accuracy of GNN. Therefore, GNN has the highest prediction accuracy among all the models.
After constructing the new energy financial market risk early warning model, the sample data interval selected in this paper is the daily data of WTI crude oil futures yield from 2015 to 2023 to verify the validity of the model. Among them, the data from the first 50 months is the training set, and the data from the latter month is the test set.
The new energy financial risk early warning model constructed in this paper is compared and analysed with other prediction models in order to prove that the prediction performance of the graph neural network-based prediction model in this paper is better than that of other prediction models.
The results of the comparative analysis between the new energy financial risk early warning model proposed in this paper and other prediction models are shown in Table 7. Among them, the comparative models include single support vector machine model (SVM), multivariate grey prediction model (GM(1, N)), multivariate autoregressive sliding average model (ARMAX), BP neural network prediction model (BP), and multivariate regression model (RM) Specific analyses of the results are as follows.
Comparative analysis
| Prediction model | GNN | SVM | ||||||
| Hysteresis | First-order | Second order | Third order | Fourth-order | First-order | Second order | Third order | Fourth-order |
| MAPE/% | 3.52 | 4.14 | 4.96 | 5.54 | 3.78 | 4.25 | 4.92 | 5.76 |
| MAE | 0.756 | 0.824 | 0.945 | 1.354 | 0.757 | 0.824 | 0.927 | 1.288 |
| RMSE | 0.598 | 0.635 | 0.778 | 0.897 | 0.611 | 0.676 | 0.790 | 0.954 |
| FVD | 0.891 | 0.837 | 0.775 | 0.714 | 0.837 | 0.797 | 0.785 | 0.729 |
| Prediction model | GM(1,N) | ARMAX | ||||||
| Hysteresis | First-order | Second order | Third order | Fourth-order | First-order | Second order | Third order | Fourth-order |
| MAPE/% | 4.58 | 5.96 | 5.27 | 6.35 | 6.59 | 7.57 | 8.04 | 8.59 |
| MAE | 0.896 | 0.974 | 1.345 | 1.578 | 1.781 | 1.995 | 1.653 | 1.907 |
| RMSE | 0.665 | 0.725 | 0.787 | 0.965 | 0.965 | 0.993 | 1.042 | 1.214 |
| FVD | 0.824 | 0.810 | 0.726 | 0.722 | 0.776 | 0.721 | 0.807 | 0.753 |
| Prediction model | BP | RM | ||||||
| Hysteresis | First-order | Second order | Third order | Fourth-order | First-order | Second order | Third order | Fourth-order |
| MAPE/% | 7.89 | 8.65 | 9.75 | 10.24 | 9.03 | 9.75 | 10.03 | 11.48 |
| MAE | 1.635 | 1.962 | 2.653 | 2.369 | 2.214 | 2.324 | 2.635 | 2.989 |
| RMSE | 0.797 | 0.804 | 0.979 | 1.324 | 0.706 | 0.927 | 1.333 | 1.502 |
| FVD | 0.735 | 0.747 | 0.614 | 0.685 | 0.724 | 0.643 | 0.659 | 0.657 |
The prediction based on the graph neural network is significantly better than the other comparative prediction models, with the values of MAPE, MAE, and RMSE of 3.52%, 0.756, 0.598, and the prediction validity of 0.891, respectively. In terms of the different orders, the first order denotes the prediction by using one period of lagging of the influencing factors. Similarly, the fourth order indicates a prediction using a lag of four periods for the influencing factors.Obviously, all the indicators show that the prediction effect of energy financial risk warning using lag one of the influencing factors is better than the prediction effect of lag two, lag three, and lag four. The difference between MAPE, MAE and RMSE in lag one and lag four is 2.02, 0.598 and 0.299, respectively, and the difference in predictive validity is 0.177, which is a big difference in all four indicators. Because the new energy financial market risk and impact have a close linkage, that is, when the macro economy or new energy market and other risks occur, it will soon be able to be transmitted to the new energy financial market, triggering the price fluctuations of the new energy financial market, which in turn generates risk. Therefore, when any influencing factors related to the new energy financial market change, the new energy financial market is likely to be at risk and needs to be warned early.
For different types of multifactor prediction models, SVM has the highest prediction accuracy, GM(1, N) has the second highest prediction accuracy, followed by ARMAX, then the multiple regression model and the worst prediction accuracy is the BP neural network model.
In summary, based on the results in the table, the following conclusions can be drawn.
One, the new energy financial risk early warning model based on the graph neural network used in this paper has the highest prediction accuracy as well as prediction validity, and the model is able to effectively capture the linear and nonlinear characteristics of energy financial market prices.
Second, the prediction performance of the combined prediction model is better than that of individual prediction models.
Third, for the new energy financial risk market, the prediction method based on machine learning and statistical theory is better than a single prediction model based on artificial intelligence or a single prediction model based on statistical measurement theory.
This paper introduces the energy market risk spillover effect and the energy market risk transmission theory, uses the GARCH model to carry out the analysis of the risk spillover effect of the carbon market and the new energy market, and concludes that there is a two-way spillover effect between the carbon market and the new energy market. Using graph neural networks to build an early warning system for new energy financial risks, preventing new energy financial market risks in a timely manner.
The GARCH(1,1) model is used to carry out the yield data test analysis, eliminate the conditional heteroskedasticity, and obtain the values of each parameter in the carbon market, coal market, crude oil market and new energy market. Where