Intelligent capture analysis model for high-speed toll evasion vehicles based on vehicle re-identification algorithm

Published Online: Mar 17, 2025
Received: Oct 22, 2024
Accepted: Feb 15, 2025
DOI: https://doi.org/10.2478/amns-2025-0181
Keywords
© 2025 Sinan Song, published by Sciendo
This work is licensed under the Creative Commons Attribution 4.0 International License.
Under the charging mode of China's highway “one network”, for long-distance cross-provincial vehicles, the highway single toll amount is larger, and the temptation of illegal benefits brought by toll evasion is greater than that in the past [1-2]. At the same time, due to the highway network is more and more complex, evasion of the audit is more and more difficult, a few unscrupulous owners use a variety of means to evade payment of highway tolls without being detected. Therefore, how to quickly find and control the illegal owner's highway toll evasion and build an efficient and powerful auditing system are the urgent problems for highway operators and managers.
Vehicle re-identification algorithm, also known as vehicle re-identification, aims to retrieve and correlate images of the same vehicle identity captured by different cameras, and identify the target vehicle through the image or video sequence [3-4]. As vehicles passing through the highway will be detected by different angles and resolutions of the monitoring equipment, when the unscrupulous car owners in the highway using various ways to evade the toll, generally will leave the corresponding behavioral characteristics of information. By detecting vehicles in each frame of the surveillance video, a data set of illegal vehicle images is constructed, and then the suspected toll evading vehicles can be identified according to the behavioral characteristics of the evading vehicles [5-7]. The use of vehicle re-identification technology on the behavioral characteristics of toll evasion vehicles, the establishment of the corresponding management measures and comical shuttle system can effectively regulate the order of the passage of vehicles, control the vehicle refuses to pay, fleeing to pay, underpayment of highway tolls, to avoid the loss of state-owned assets, and to maintain the fairness of the transportation market [8-10].
Liu, X. et al. show that the construction of vehicle re-identification image dataset needs to address two important requirements, namely, capturing a large number of vehicles in a real traffic environment and realizing cross-camera vehicle search, and propose a large-scale benchmark dataset “VeRi” to meet the requirements and a benchmark model that combines the color, texture, and high-level semantic information [11]. Sun, W. et al. introduced a multi-feature learning model with enhanced local attention (MFELA), which enhances the global feature representation by extracting multi-scale semantic features, and enhances the attention to the local region by using the region batch discard block method to combine the feature representations of the global branch and the local branch to achieve a better performance of vehicle re-recognition [12]. Liu, X. et al. designed a region-aware depth model to learn local features with differences as a way to aid vehicle re-recognition efforts, and the method achieved better performance in large-scale datasets [13]. Liu, X. et al. proposed a vehicle re-recognition method with global-regional features, which describes additional local details based on recognizing the appearance of a vehicle in order to enhance the ability to differentiate between the global contexts, and utilizes a group loss algorithm to optimize the distances within and between groups of vehicle images for a more convenient and efficient recognition process [14]. Zakria, Cai, J. et al. constructed a vehicle re-recognition system with a global channel and a local-region channel, which firstly extracts global feature vectors of the images in the database to initially recognize the vehicle, and subsequently extracts more discriminative and salient features from different regions of the vehicle [15]. Shen, F. et al. constructed a vehicle re-recognition model based on the graph-interactive transformer method, using the graph to extract local features with discriminative power within an image, and using the transformer to extract global features with lupanicity between images [16]. He, B. et al. introduced a partially regularized discriminative feature preservation method, which enhances the ability of perceiving subtle differences, and constructed a framework combining global constraints and local constraints modules for end-to-end training, which significantly improved the performance of vehicle re-recognition algorithms [17].
Tian, X. et al. emphasized that the key to vehicle re-recognition is to extract discriminative vehicle features, so they constructed a combined approach for feature extraction, applied a three-branch adaptive attention network to extract the important features of the vehicle, and then used a global relational attention approach to capture the global structural information, and finally used multi-granularity feature learning to capture the fine-grained local information [18]. Shen, J. et al. applied an attention model to achieve robustness and efficiency of vehicle re-identification algorithms and proposed an end-to-end partitioned and fused multibranch network (PFMN), which does not require additional annotations or attributes to learn vehicle discriminative features with a high degree of effectiveness [19]. Rong, L. et al. similarly proposed a multibranch network model that employs a fusion of global and local features to capture the vehicle information, and embedded a channel attention module to achieve personalized feature extraction of the target vehicle, and then using a weighted local feature control method to reduce the background information and noise information to effectively improve the accuracy of vehicle re-identification [20]. Yang, J. et al. investigated a method to learn discriminative information from vehicle images with multiple viewpoints, and proposed a two-branch feature learning network, which utilizes the pyramid local attention module to learn local features at different scale local features, then the spatial attention module learns the attention global features, and finally the pooled local and global feature vectors are used for identity re-identification [21].
To summarize, the research on VRI technology is advancing, enhancing the accuracy, robustness, and real-time performance of vehicle recognition in complex environments.However, some shortcomings still exist in existing research, such as complex recognition environments and the similarity of identified vehicles.Therefore, the study proposes an intelligent capture analysis model for highway toll evasion vehicles based on the VRI algorithm.By combining multi-dimensional self-attention structure with multi-dimensional feature fusion, the accuracy of the intelligent capture analysis model for toll-evading vehicles can be improved.The research aims to maintain the order of highway operations and conduct precise inspections of vehicles that are evading fees. The innovation lies in the combination of deep learning and computer vision, which can automatically learn complex features in vehicle images, thereby achieving high-precision vehicle recognition.
This section has two parts. Firstly, a vehicle recognition algorithm based on multidimensional self-attention is proposed. Secondly, a VRI method relying on multi-dimensional feature fusion relying on multi-dimensional self-attention is designed, forming an intelligent capture and analysis model for highway toll evasion vehicles based on the vehicle re identification algorithm.
The recognition module in the intelligent capture analysis model for highway toll evasion vehicles consists of a vehicle recognition method on the ground of multi-dimensional self-attention and a vehicle recognition algorithm on the ground of multi-dimensional feature fusion. The vehicle recognition algorithm based on multi-dimensional self-attention can effectively extract significant features of the appearance of vehicles that avoid fees.The multi-dimensional feature fusion algorithm for vehicle recognition fuses the extracted features in multiple dimensions.Traditional VRI methods that focus on attention only use global or local attention mechanisms for feature learning and information processing. However, due to insufficient consideration for scale changes, these approaches appear inefficient in extracting and utilizing multi-dimensional information [22-23]. Multi-dimensional self-attention can help the model identify prominent feature regions in vehicle images. Therefore, a vehicle recognition method based on multi-dimensional self-attention is designed to enhance VRI accuracy according to vehicle appearance features.The vehicle recognition algorithm model based on multi-dimensional self-attention is displayed in Figure 1.
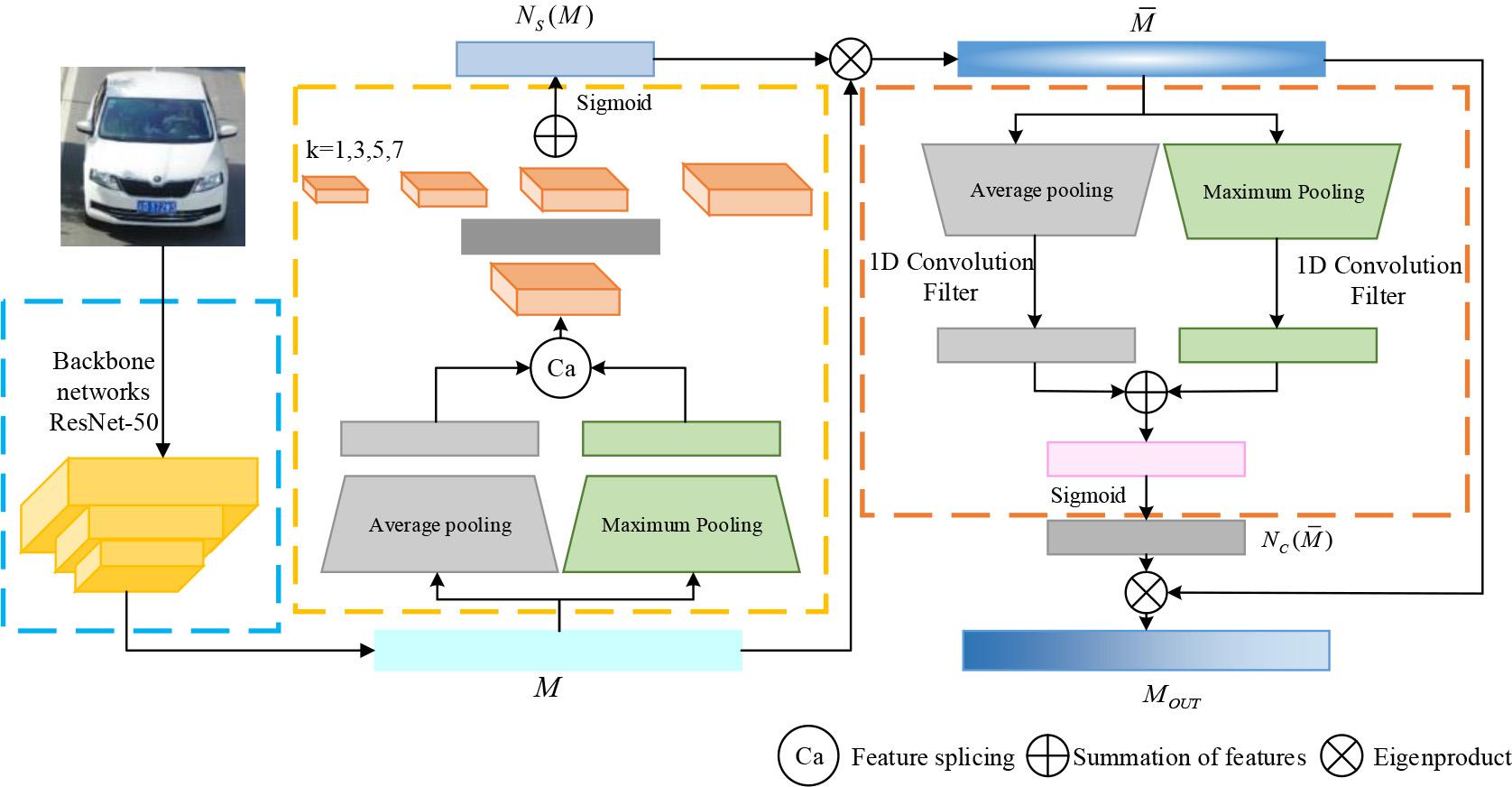
Schematic model of vehicle recognition algorithm based on multi-resolution self-attention
As shown in Figure 1, the vehicle image undergoes 50 layers of residual network to extract initial features, and then enters the multi-dimensional spatial attention module. Different sized convolution kernels are applied to extract multidimensional features, generate spatial attention, and enhance the feature map. Subsequently, channel attention maps are generated using spatiotemporal pooling, one-dimensional convolution, and activation functions through the channel attention module.Finally, channel attention is fused to produce optimized feature maps.The calculation of the VRI algorithm using multidimensional self-attention is displayed in Equation (1).
In equation (1),
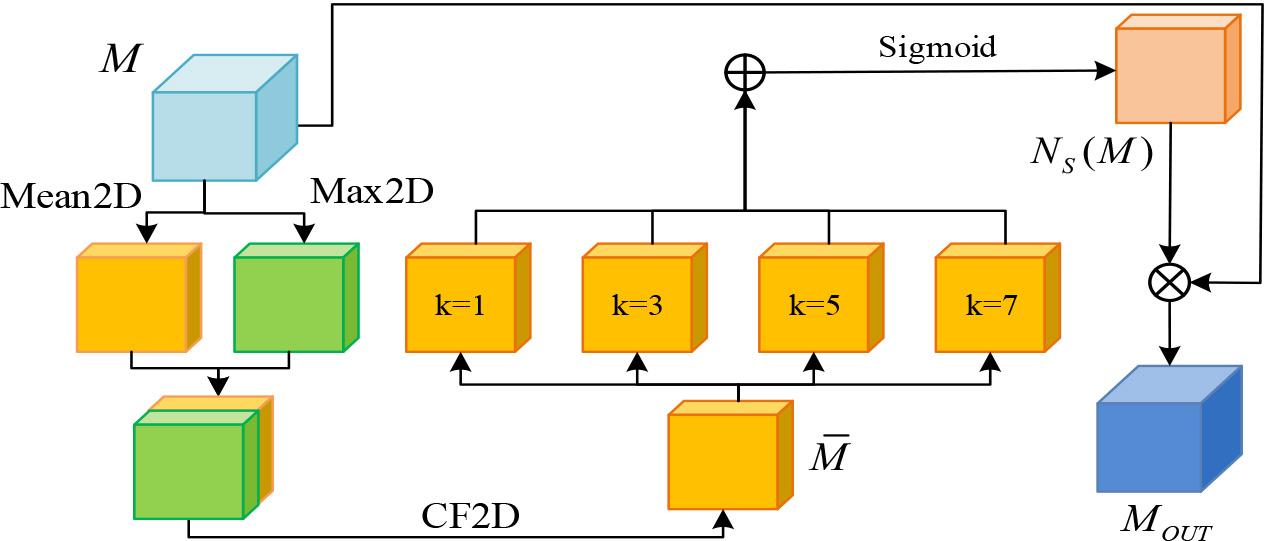
Multi-scale spatial attention module structure
In Figure 2, the input data
In equation (2),
In equation (3),
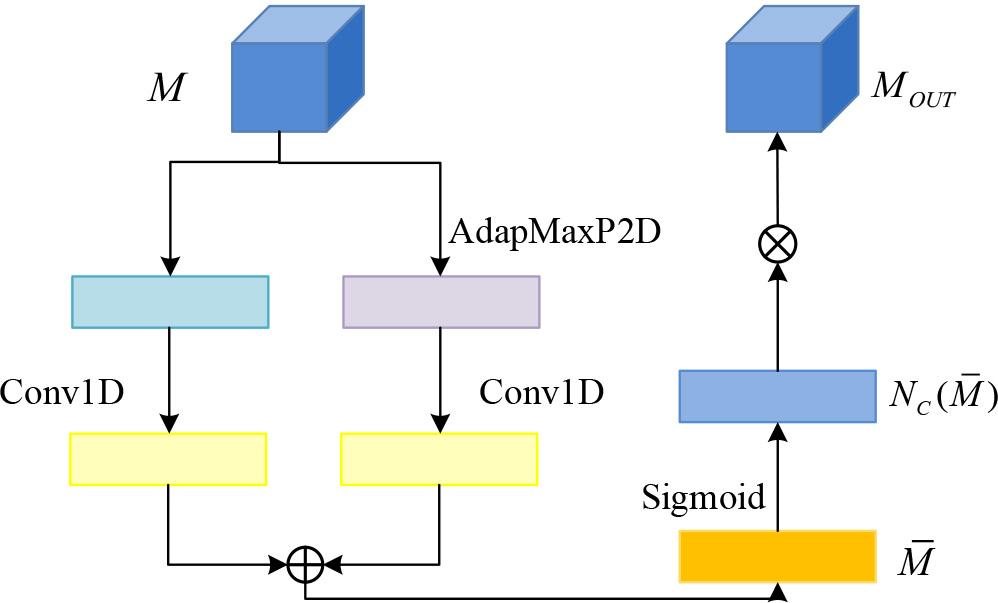
Channel attention structure
In Figure 3, the feature map
In equation (4),
In equation (5),
In equation (6),
In equation (7),
The VRI algorithm on the ground of multi-dimensional self-attention can effectively extract subtle and significant features of fare evasion vehicles and accurately identify them. However, in real traffic scenes, due to factors such as the diversity of shooting angles and dimensional differences, vehicle images exhibit diverse scales, resulting in different proportions of vehicles in the images, and directly affecting the VRI accuracy [24]. Therefore, a VRI method on the basis of multi-dimensional self-attention algorithm and multi-dimensional feature fusion is proposed, which deeply extracts multi-dimensional features and fuses feature information at various scales. The calculation of multi-dimensional feature extraction is shown in equation (8).
In equation (8),
In equation (9),
In equation (10),
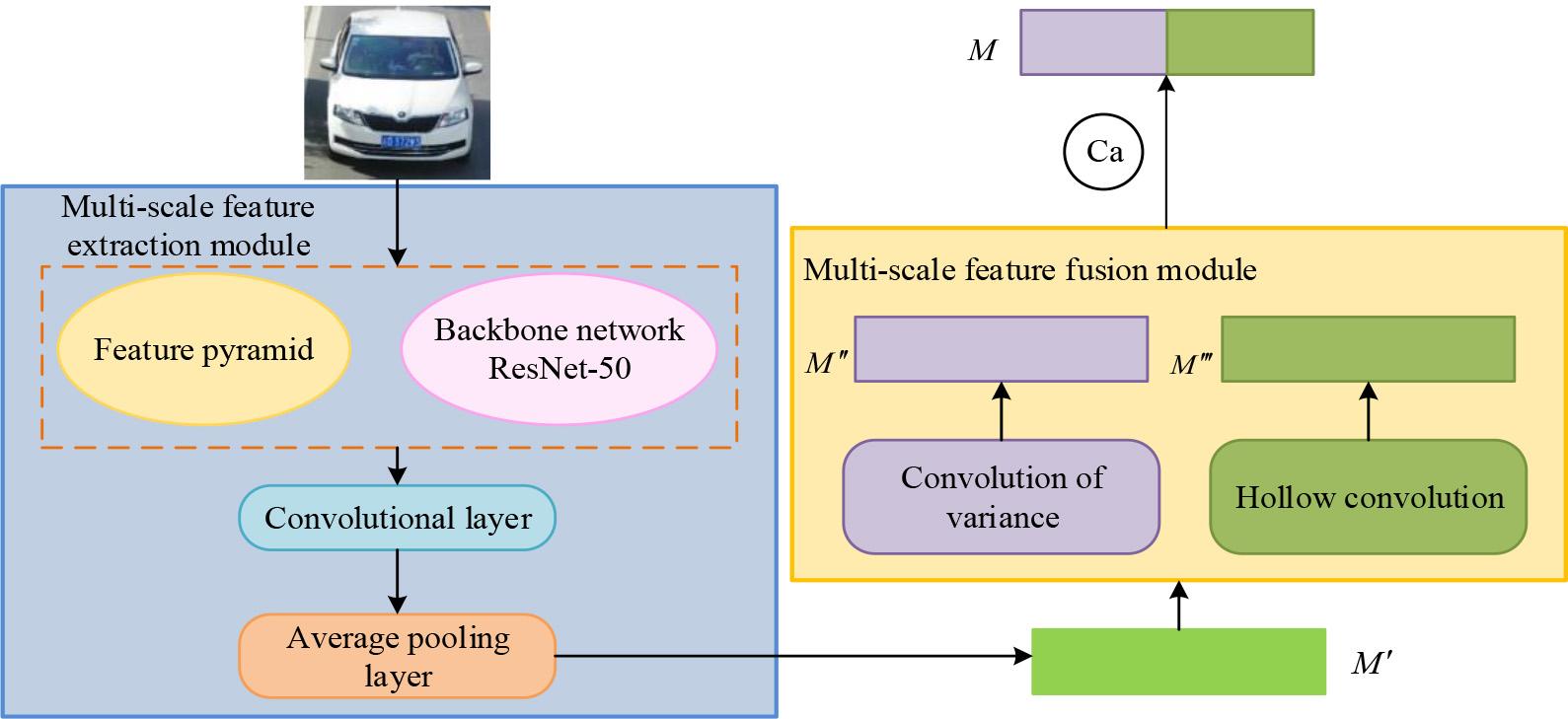
Schematic model of vehicle re-identification method based on multi-dimensional feature fusion
In Figure 4, the model has multi-dimensional feature extraction and complementary fusion modules. The feature extraction module is based on a residual network of 50 layers and a feature pyramid, extracting rich semantic and scale features, integrating semantics through convolution and pooling, and generating an output feature map
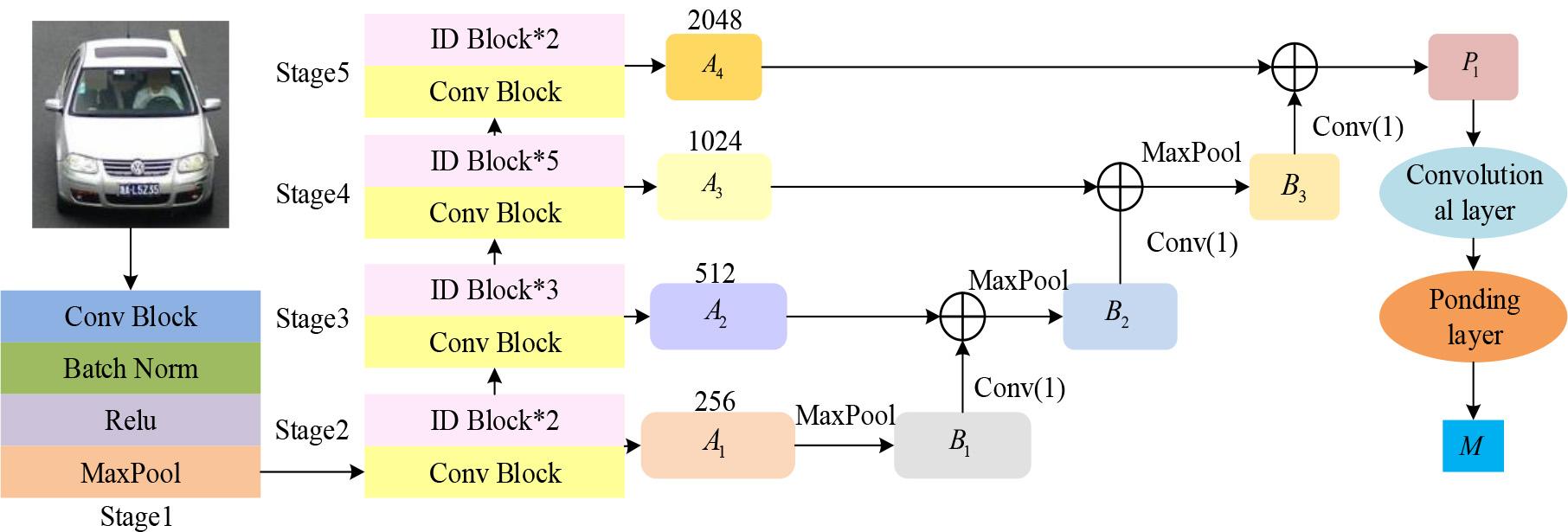
The structure of multi-scale feature extraction module
In Figure 5, the core principle of the module is to introduce a feature pyramid on the basis of a residual network of 50 layers, and fuse the multi-dimensional feature maps from Stage 2 to Stage 5. Based on maximum downsampling, 1x1 convolution matching channels, and adding them up, the output feature map is passed layer by layer to the lower layer, followed by multi-dimensional spatial attention convolution and average downsampling to obtain multi-dimensional features. The complementary fusion module integrates these features using dilated convolutions with dilation rates of 2, 3, and 4 and deformable convolutions with kernel sizes of 1, 3, and 5, respectively. Then, the fused features are concatenated through channels to form more robust multi-dimensional features, forming a more robust multi-dimensional feature.
To demonstrate the effectiveness and superiority of the multi-dimensional self-attention and vehicle recognition method on the ground of multi-dimensional feature fusion, experiments are conducted using window11 as the operating system and TensorFlow as the experimental platform, with detailed analysis of the experimental results.
The experiment uses VeRI-776 and VehicleID as datasets. The experimental setup is displayed in Table 1.
| Name | Imprint |
|---|---|
| Systems | ubuntu18.04 LTS |
| CUDA | 10.2 |
| cuDNN | 7.6.5 |
| Programming languages | Python3.7.7 |
| Deep learning frameworks | Pytorch |
| CPU | Intel(R)Core(TM)i7-12700H |
| GPU | RTX 3090Ti |
| Display memory | 24GB |
| Random access memory | 64GB |
| Hard disk | 2TB |
| Optimizers | Adam |
To validate the overall impact of each module in the vehicle recognition method on the basis of multi-dimensional self-attention, the comparative algorithms used in the study are: adding Relation-Aware Global Attention (RGA) module to the backbone network, adding an Efficient Channel Attention Network (ECANet) module, and adding a Convolutional Block Attention Module (CBAM) module. These algorithms are named M1, M2, M3, and M4, respectively, and compared with the proposed algorithm. Comparative analysis is performed on the VeRI-776 and VehicleID, as displayed in Figure 6.
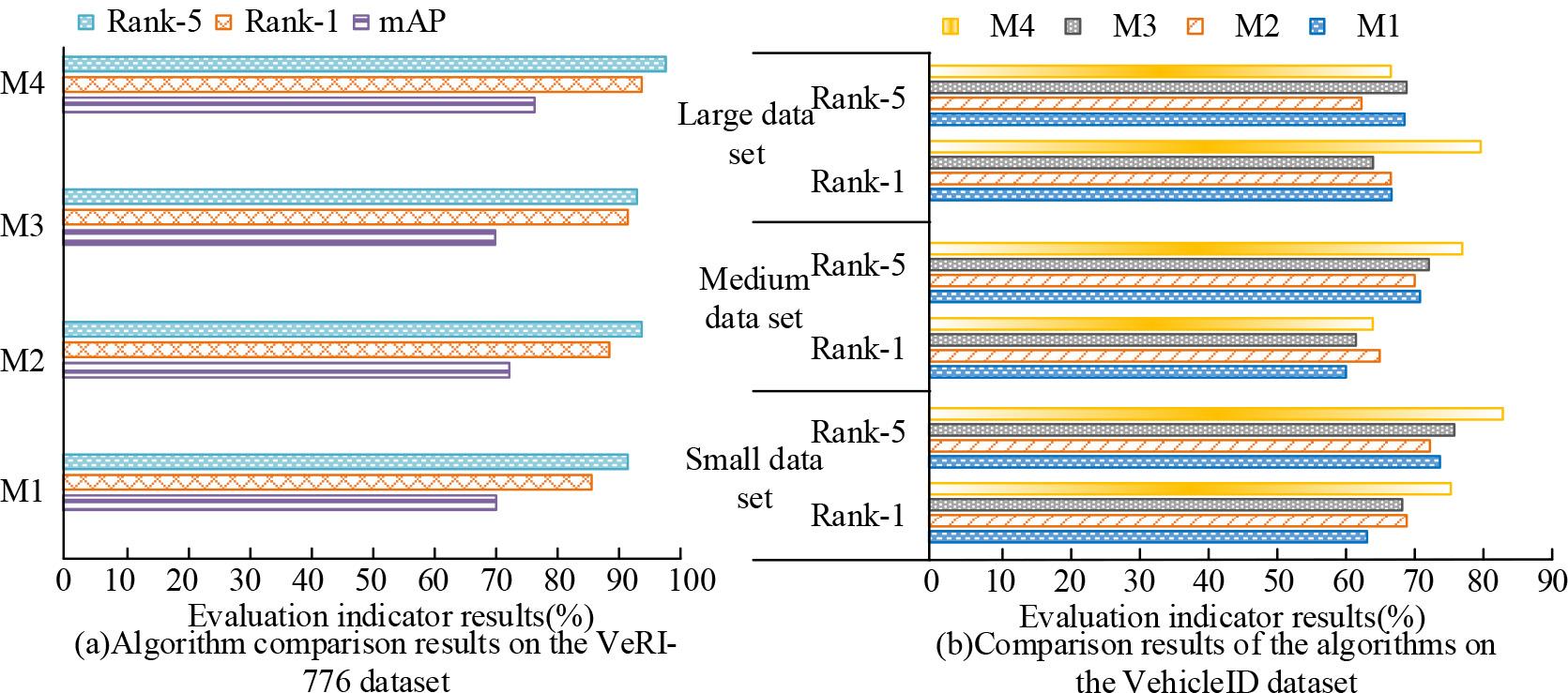
Schematic of comparison experiments on VeRI-776 and VehicleID datasets
According to Figure 6 (a), M4 performed the best compared with other algorithms, with mAP of 76.42%, Rank-194.64%, and Rank-5 of 98.15%. As shown in Figure 6 (b), on the Small dataset, the Rank-1 and Rank-5 of the M4 were 76.42% and 83.52%, respectively, both of which were optimal. To further validate the effectiveness of the vehicle recognition algorithm on the basis of multi-dimensional self-attention proposed in the study, the VeRI-776 is separated into training and testing sets in a 7:3. Figure 7 shows the results.
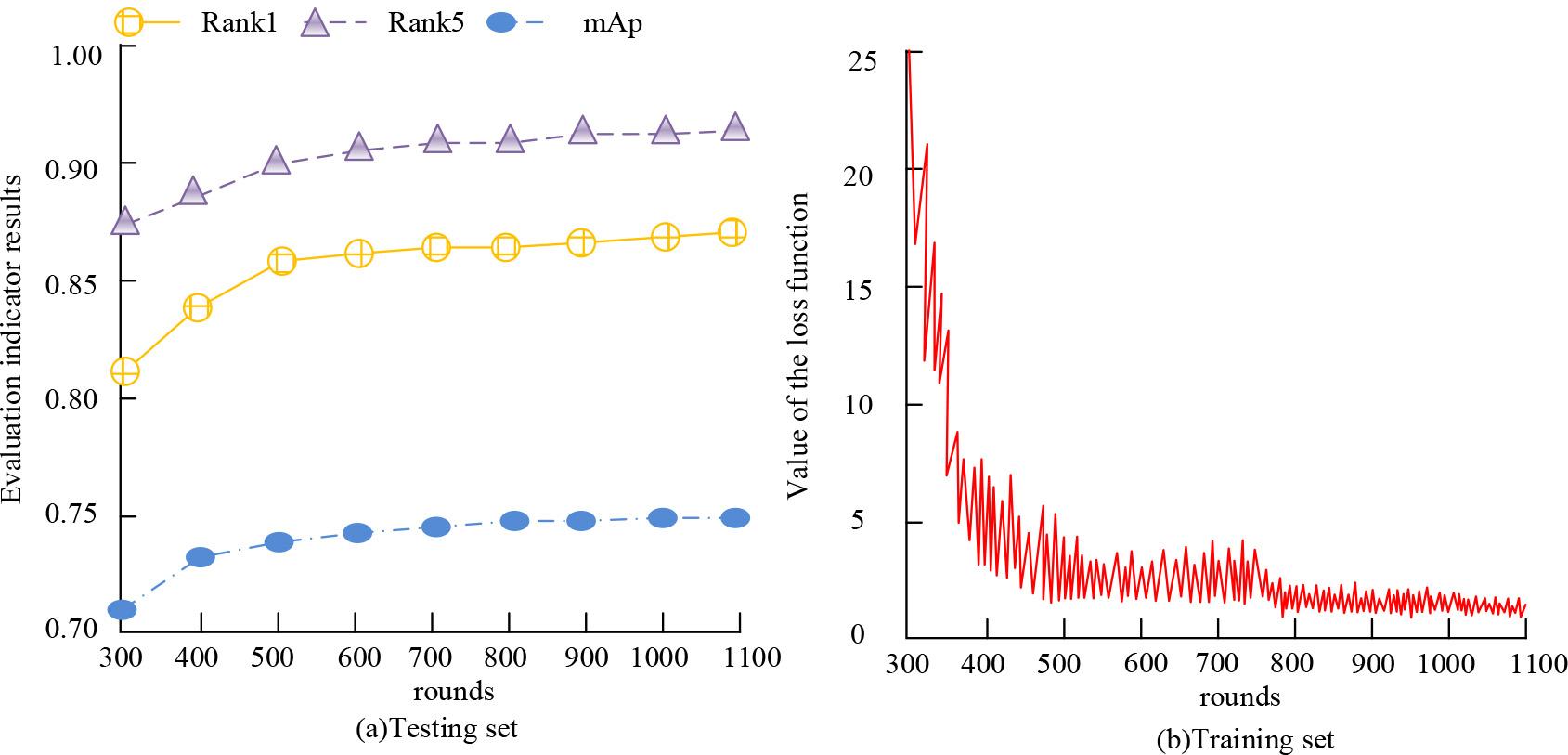
Evaluation indicators and loss functions
As shown in Figure 7 (a), with the increase of the round, the mAP, Rank-1, and Rank-5 of the vehicle recognition algorithm based on multi-dimensional self-attention gradually increased and eventually stabilized at 75%, 87%, and 92%, respectively. In Figure 7 (b), with the increase of rounds, the loss function value gradually decreased and converged towards 0, which proved the effectiveness of the algorithm.
To verify its effectiveness, the experimental environment configuration used for training remains unchanged. The optimized residual network architecture with 50 layers is selected as the main network framework for feature extraction, and pre-trained parameters from the ImageNet dataset are applied to initialize this backbone network to improve model performance. Three comparison methods are set up, namely Position Map Regression Networks (PRN), Uncertainty-aware Multi-shot Teacher-Student (UMTS), and Multi-Scale Deep (MSDeep), and compared with the proposed VRI method on the basis of multi-dimensional feature fusion on the VeRI-776 and VehicleID, as displayed in Figure 8.
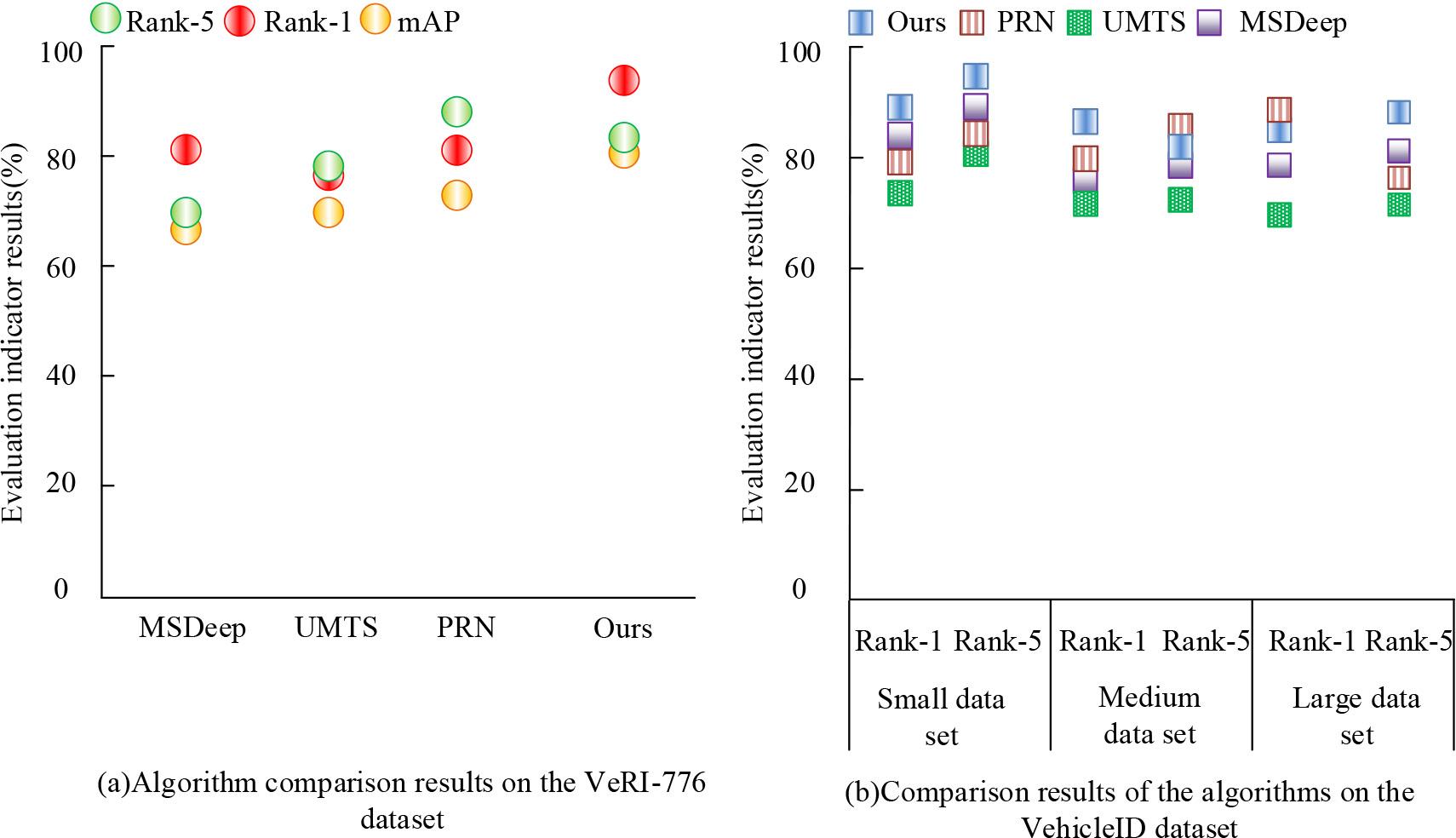
Comparative experiments of various methods on VeRI-776 and VehicleID
According to Figure 8 (a), on the VeRI-776, the multi-dimensional fusion VRI method had the best mAP and Rank1, which were 83.65% and 96.32%, respectively. From Figure 8 (b), the proposed method performed well on the VehicleID, especially on the Small dataset, where Rank-1 and Rank-5 were both the best, with 91.42% and 96.35%, respectively. The fusion experiment of multi-dimensional self-attention proposed in the study with a multi-dimensional feature fusion vehicle recognition algorithm is displayed in Table 2.
| VehicleID dataset | VeRI-776 dataset | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Methodologies | Small dataset | Medium dataset | Large dataset | mAP | Rank-1 | Rank-5 | |||
| mAP | Rank-1 | mAP | Rank-1 | mAP | Rank-1 | ||||
| Baseline | 82.67 | 92.31 | 88.12 | 90.26 | 77.29 | 95.84 | 82.36 | 92.17 | 94.67 |
| Baseline+multi-scale attention mechanism | 86.22 | 95.14 | 88.2 | 90.24 | 77.84 | 90.59 | 83.15 | 93.25 | 95.49 |
| Baseline+multi-scale information fusion | 84.57 | 97.12 | 88.11 | 95.12 | 74.48 | 91.13 | 83.64 | 94.36 | 96.17 |
| Multi-scale attention mechanism+multi-scale information fusion | 89.23 | 98.65 | 88.26 | 96.16 | 77.97 | 94.62 | 84.69 | 97.64 | 98.15 |
According to Table 2, on the VeRI-776 dataset, the combined VRI performance significantly improved, with mAP reaching 84.69%, Rank-1 reaching 97.64%, and Rank-5 reaching 98.15%. On the VehicleID dataset, after combining multi-dimensional attention and feature fusion algorithms, the mAP of the Small set increased by 6.56%, the Medium set by 0.14%, and the Large set by 0.68%. By incorporating multi-dimensional self-attention structures separately or multi-dimensional feature fusion, the model's metrics were improved, and the model results were optimal when both were combined. This demonstrates the effectiveness of the proposed vehicle recognition algorithm that combines multi-dimensional self-attention with multi-dimensional feature fusion. This indicates that the study effectively improves the performance of the intelligent capture and analysis model for highway toll evasion vehicles based on VRI algorithm by combining multi-dimensional self-attention structure with multi-dimensional feature fusion.
Multiple challenges include feature variation caused by equipment differences in highway toll evasion vehicle recognition, inter class confusion caused by the diversity of traffic scenes, intra class similarity, and detail preservation. The study improved the vehicle recognition method by combining multi-dimensional self-attention with multi-dimensional feature fusion. An intelligent capture analysis model for highway toll evaders based on VRI algorithm was proposed, further recognizing highway toll evaders. The experimental results showed that on the VeRI-776, the mAP, Rank-1, and Rank-5 using multi-dimensional attention modules were optimal, with values of 76.42%, 94.64%, and 98.15%, respectively.On the Small dataset of VehicleID, the multidimensional self-attention achieved optimal performance, with Rank-1 and Rank-5 values reaching 91.42% and 96.35% respectively.On the VeRI-776 dataset, the VRI method based on multi-dimensional feature fusion achieved the best results in mAP and Rank1 evaluation metrics, with 83.65% and 96.32%.On the VehicleID, the combined model metrics were further improved. The mean absolute price of the Small test set increased by 6.56%. On the dataset, the performance indicators of VRI were further improved. Especially when combining multi-dimensional self-attention and multi-dimensional feature fusion, the mAP reached 84.69%, Rank-1 reached 97.64%, and Rank-5 reached 98.15%. Overall, the model that integrates multi-dimensional self-attention structures with multi-dimensional features has practical application value in improving the intelligent capture of highway toll evaders. Future research can further explore its application in real-world scenarios and consider multimodal data integration to achieve broader applications and higher recognition performance.